


As projects like Project Cassini and SOAFEE (Scalable Open Architecture for Embedded Edge) are being developed to support standards-based Cloud Native Edge development/deployment environments, VirtIO is a key building block designed to enable these efficient EDGE development environments. GPU virtualisation is one of the more complex components to enable in VirtIO. This blog will discuss some of those challenges along with the progress the Linaro development teams are making in this space.
VirtIO based block and network devices benefit from being relatively simple abstractions which map well onto the underlying hardware. This has been helped by the many rounds of optimisation they have been through to minimise the virtualisation overhead penalty.
Graphical Processing Units (GPUs) are much harder to cleanly abstract due to the wide range of hardware that exists. Back in the simpler days of 2D graphics any particular hardware could only support a specific range of memory layouts and colour depths. As technology advanced graphics engines gained various disparate abilities to copy regions of memory, manage sprites or rotate textures. The situation hasn’t gotten simpler with the advent of 3D. A modern GPU is really a special purpose processor which has been optimised to execute the large numbers of parallel calculations required to render a modern scene. It’s not surprising a lot of modern supercomputers have these number crunching pipelines at the core.
Unlike most CPUs however, the details of the GPUs execution model are often hidden from the user. Typically GPUs are either programmed with a higher level API which is then translated by a proprietary binary blob into those secret hidden instruction streams that are fed to the GPU. While there are a number of open APIs for programming GPUs that aim for portability between GPUs there are also vendor specific libraries which are tied to a particular hardware.
All this has made the virtualisation of GPUs a particularly challenging field. There are broadly two approaches that can be used: Virtual Functions and API Forwarding.

Virtual Functions
This approach is similar to what is done with other high performance virtualisation hardware where a single physical card is partitioned into a number of Virtual Functions (VF). Each VF can then be shared with a guest which then drives it directly much like it would if running as the host.
For the server space, the major GPU players (Intel, AMD, nVidia) support SR-IOV on their high end GPU cards. This uses the well established PCI partitioning to divide the VFs between the guests. However there are two challenges with GPUs aimed at the automotive and industrial market:
- Lower number of VFs (maybe only 2, requiring abstraction)
- Platform specific partitioning schemes
GPUs supporting VF partitioning are still fairly rare in the market and those that do exist often only support a limited split which means a fully abstracted virtual GPU is still needed to multiplex multiple guests with graphics requirements.
As these devices are often platform devices (i.e. directly mapped memory, not a PCI device) the support for assignment of these VFs needs coordination between the firmware, platform and the drivers. This complicates things from the point of view of clean abstractions.
Software aided virtual functions
To address these limitations, various software aided approaches have been adopted to make up for the lack of pure hardware support.
The original form of this is an extension called Mediated Devices (mdev) which, hardware permitting, allows the host kernel to partition up a device. Currently the only in-kernel drivers that support this are the Intel i915 driver and one s390 crypto driver.
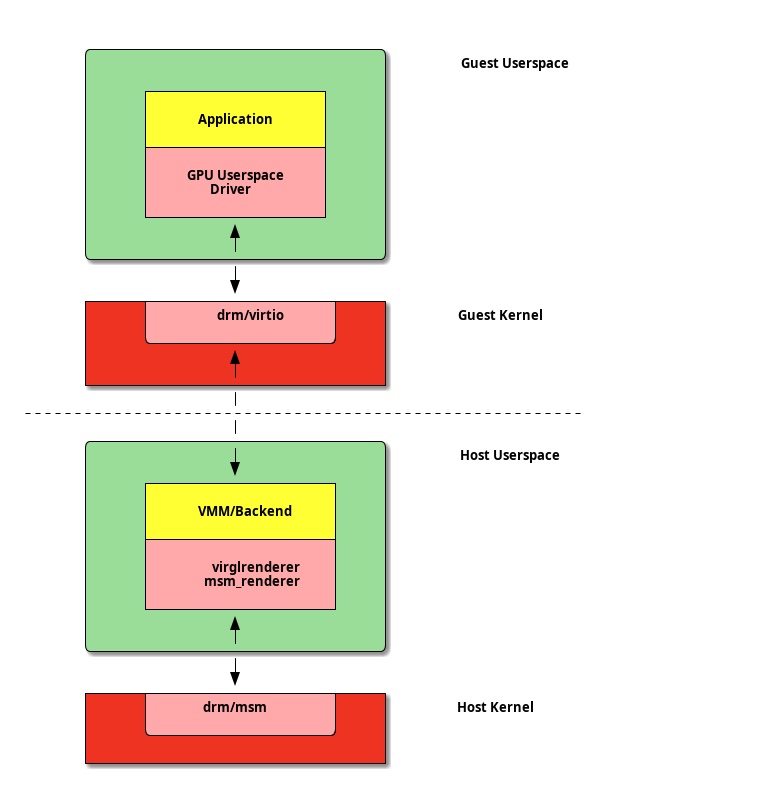
A more recent approach is to leverage an extension to virtio-gpu known as the Native Context. This re-uses the VirtIO machinery for a number of common functions but also exposes the native context directly to the guest. The guest ends up running a lightly modified version of the native GPU driver which is made VirtIO aware in combination with changes made to the rendering backend to support a custom guest/host protocol for that particular GPU.
API Forwarding
The other approach seen in GPU virtualisation is API forwarding. This works by presenting the guest with an idealised piece of virtual hardware which closely maps onto the requirements of the shared library abstractions. The original 3D acceleration for VirtIO GPU was based on OpenGL. The device provides a virtual OpenGL device called VirGL which is based on the Gallium3D interface. This allows the guest to simply feed the device a series of OpenGL commands along with a universal GPU independent shader intermediate language. At the back end these commands are fed into virglrenderer which will then render through the host GPU.
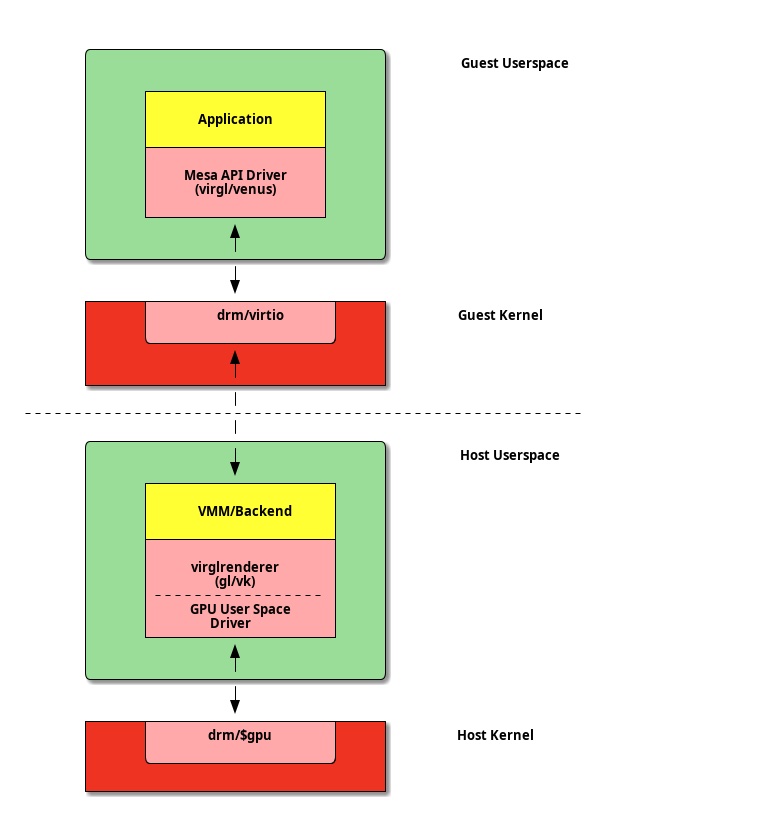
The main complaint against the VirGL approach is efficiency. While fine for running a smooth desktop experience, performance is well below what you would expect running directly on the host. One reason for this could be that the venerable OpenGl programming model is a little too abstract from the way modern GPUs tend to be programmed. Combined with the inevitable virtualisation overhead this exacerbates its performance problems.
A more modern API called Vulkan has been developed to replace OpenGL which is a much lower level programming API more closely aligned to how modern graphics hardware works. It also unifies graphics with compute workflows (which make up a significant use case of GPUS) under a single API. While support for Vulkan over virtio-gpu has yet to land in projects like QEMU a number of alternative Virtual Machine Monitors (VMMs) are able to use this mode to provide a more efficient virtual GPU implementation.
Finally there is a third protocol, Wayland, which doesn’t target the GPU directly but is intended for talking to a 3D enabled display server. This allows guest applications running in the guest to be seamlessly integrated with the hosts display manager. The original use case was for Linux applications in CrosVM guests to integrate with the ChromeOS host. Interestingly there are extensions to the protocol targeting in-vehicle entertainment systems.
Comparing the two approaches
Virtual functions look like the way forward for those wanting to wring as much performance out of their graphics hardware as possible by keeping abstractions as lightweight as possible. There is also a good security argument that by isolating a complex graphics stack in the guest domain library exploitation risks can be mitigated. GPUs by their very nature have to deal with processing lots of untrusted guest data.
However there are some disadvantages to this pass through approach. In the context of Cloud Native development the biggest problem is binding the guest code to a particular GPU architecture which means there is less portability between the cloud and edge deployments.
Also for Linaro, as a company which works predominantly with open source, adding support would require access to proprietary code spread across the stack rather than dealing with open source abstractions.
We think that some of the security concerns around the graphics stack can be ameliorated by using safer languages like Rust to write our VirtIO backends. However it should be noted that a large chunk of the backend will still eventually end up being processed on common C libraries. One approach to mitigating the risk of exploits in the privileged host is to move the graphics backend into a separate virtual machine (sometimes called a driver domain). This way if the daemon is breached the attacker should still be contained in a relatively limited environment.

How this relates to Project Orko
Project Orko is the spiritual successor to our previous virtualisation project Stratos. We are working on integrating a number of VirtIO devices into a reference SOAFEE platform to accelerate their adoption. With multimedia being a big driver of automotive workloads, having a functional GPU solution is important. Initially there are two pieces of work planned out for GPU support.
Measuring the cost of abstraction
While there are some anecdotes about the performance of VirGL on some systems we have yet to see a comprehensive measurement of the costs of these abstractions on ARM hardware. We want to know if these newer graphics pipelines are going to be usable for handling workloads potentially as heavy as running AAA games without too much overhead.
For QEMU several groups have proposed various patches to enhance the virtio-gpu device with various extensions. We intended to help with review while also integrating those patches with QEMU’s recent xenpvh support and start making measurements on real HW on how much each abstraction costs. We also want to explore using the CrosVM Wayland backend (which uses vhost-user under the hood) and see how hard it is to integrate with QEMU’s xenpvh mode and our Xen vhost-user Frontend.
Stand-alone virtio-gpu daemon
While we are using QEMU to help with bootstrapping VirtIO devices in our SOAFEE platform, our vision is still very much to have stand-alone hypervisor independent daemons written in Rust utilising rust-vmm components. There are a number of other reasons why having a standalone daemon is useful:
- A standalone daemon is not tied to the rendering model of any particular platform (e.g. expecting a VMM to display the final renders, as it does in QEMU)
- Being able to link to a proprietary OpenGL/Vulkan library as a drop in replacement for the Mesa stack
- Take advantage of the proposed vhost-user extension with our rust-vmm traits to hide the implementation details of mapping memory and notifications on Xen (and potentially later other hypervisors)
- Without having a separate backend from the core VMM we can’t experiment with the driver domain concept I discussed earlier
Whether the best approach is to expand CrosVM’s Wayland implementation to support other GPU command streams or write a new backend from scratch remains to be seen. We are currently doing preparatory work in measuring the overhead of the various abstractions to help inform our future development direction.
As with most of the projects at Linaro all of our work is being done with the relevant upstream communities as well as being integrated into Linaro’s Trusted Reference Stack. You can find links to our JIRA and other presentations at the Project Orko homepage. If you are interested in collaborating please alex.benee@linaro.org and stay signed up to our blog for further updates.