


INTRODUCTION
Code size is critical for a wide range of software.
First, memory components can be a significant part of the overall cost of embedded devices. Reducing needed embedded memory, or being able to fit more features into it, can be very valuable on such systems.
Also, smaller code size can be beneficial on larger non-embedded systems. And it can sometimes lead to performance improvements [1], possibly due to a resulting increase in instruction cache efficiency.
In addition, increased memory usage often leads to negative effects. As an example, mobile applications are likely less downloaded if too big, because of limited storage space, application stores rules or carrier data limits. Companies like Meta, Uber and ByteDance have observed this correlation between mobile application size and user engagement, and are working on compiler optimizations to keep that size down [2] [3] [4].
While this code size metric is important, it also has many reasons to grow, like the integration of new features or performance optimizations. Let’s note that the code size (machine instructions) is only one part of an application’s size, which can also include data (included in binary size) and other resources such as images. It has been shown that the code can be the largest part of the total size [2].
Linaro Toolchain Working Group (TCWG) started working on several activities related to this topic, first aiming at helping to reduce code size of the Android Open Source Project (AOSP) [5] on behalf of Google.
This blog post will be about one of these activities: the automated tracking of code size. We’ll compare between the latest LLVM releases [6], and take a quick look at the largest variations.
CODE SIZE TRACKING USING LNT
Measuring code size on a regular basis has several benefits. It allows detection of significant regressions and improvements. It can also provide interesting feedback on specific developments, and when looking at a higher level, interesting information such as variations between releases.
For now, we have only looked at the code size generated using the -Oz optimization level. Since this level aims to find the best code size at all costs, performances do not really matter here and are not measured for now. This makes the task much easier and faster, as running the compiled binaries is not needed. Code size could also be tracked for other optimization levels in the future, after enablement of performance measurement. These other levels aim at finding tradeoffs between size and performance (-Os, -O2) or at achieving the best possible performances (-O3).
Code size is measured on SPEC (Standard Performance Evaluation Corporation) benchmarks (SPEC CPU 2006 & SPEC CPU 2017 [7] for the AArch64 target, and results are submitted to an internal LNT dashboard [8]. This is automated in a Jenkins job that runs daily [9]. This work is still ongoing. It may be productized and shared more widely in the future.
LNT (LLVM Nightly Test) is an infrastructure for performance testing. It consists of two main parts: “a web application for accessing and visualising performance data, and command line utilities to allow users to generate and submit test results to the server”.
Note that an official LLVM LNT dashboard has been available for a long time, and already provides code size figures for other benchmarks and targets [10].
There are also several TCWG Jenkins jobs that measure code size on different benchmarks, targets and optimization levels, aiming at detecting significant regressions and improvements, identifying exact responsible commits and notifying developers [11].
EVOLUTION OF THE CODE SIZE ON SPEC BENCHMARK (AT -Oz OPTIMIZATION LEVEL)
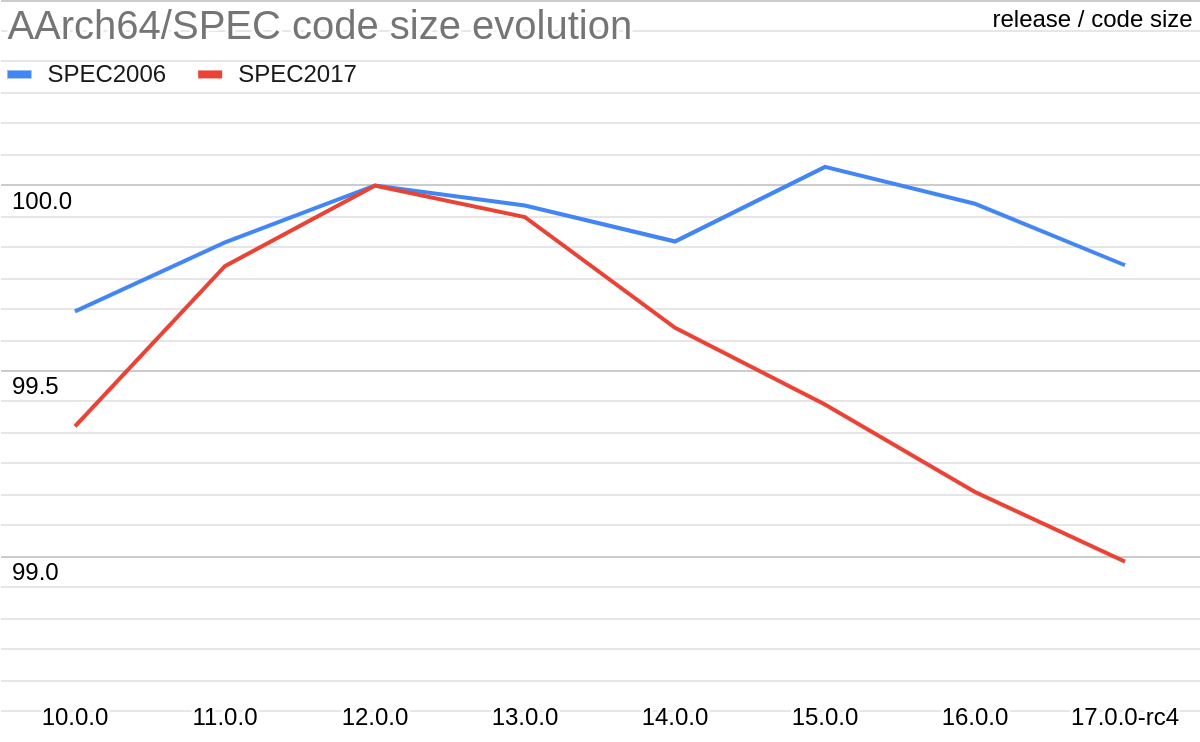
Figure 1: Evolution of code size (AArch64)
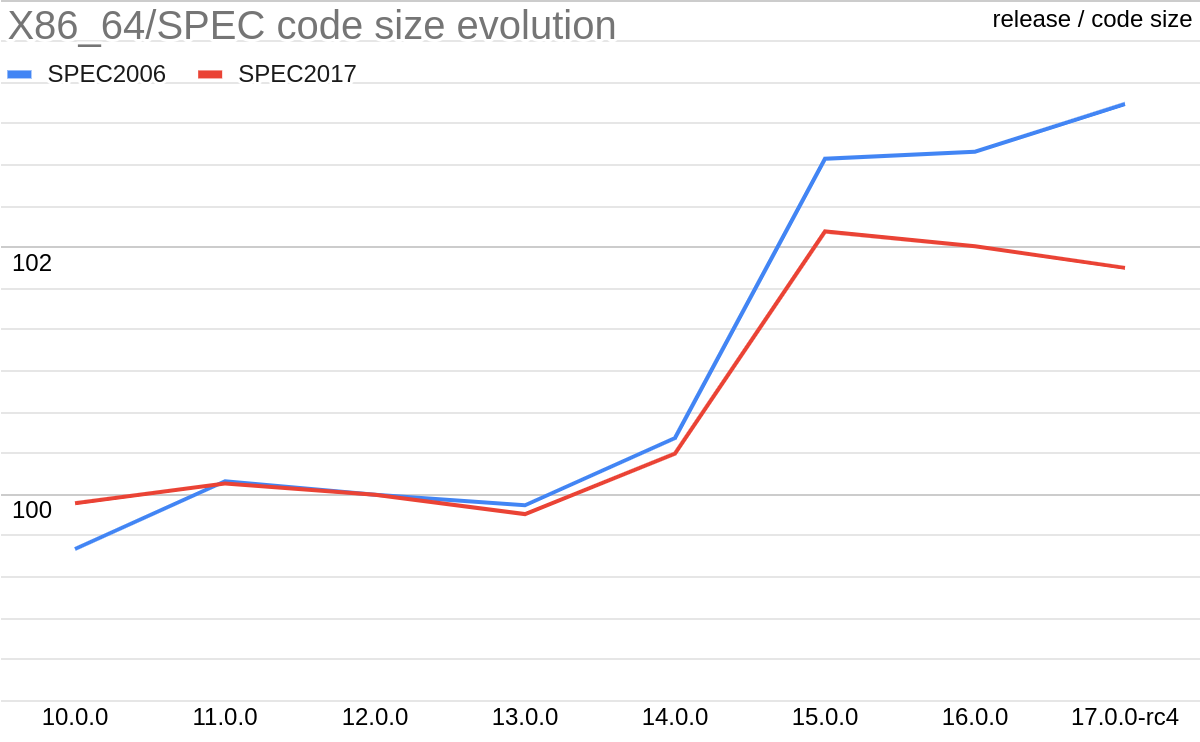
Figure 2: Evolution of code size (X86_64)
Several observations can be made by looking at code size evolution (AArch64 / -Oz) through the last LLVM releases (Figure 1 & Figure 3):
- On average, code size is smaller from release to release since LLVM 10.0. It seems this is not the case on x86_64, maybe because size is less important there (size variations on target x86_64 were not specifically analysed).
- This decrease is constant (since LLVM 12.0), but slight. Only 1% decrease on average on SPEC benchmarks since LLVM 12.0. Less if we compare with LLVM 10.0.
Note that the apparent increase between LLVM 14.0 and LLVM 15.0 is misleading. It actually corresponds to the enablement by default on linux of Position Independent Executable (PIE) generation by clang (Figure 4 V7). A decrease between LLVM 13.0 and LLVM 14.0 also corresponds to a change of default (about FP contraction, Figure 4 V5). Using -fPIE/-pie and -ffp-contract=on for fairer comparison change the variations as shown in Figure 3. Results obtained on X86_64 (Figure 2) would surely also be different doing this.
- It’s mainly something about small variations. Only a few commits stand out for both increase and decrease. Less than 10 commits lead to a code size variation (increase or decrease) of more than 0.1% on average on Smber PEC benchmarks. The biggest variations are listed in the next section.
While the variations caused by these 15 commits look small (from 0.06% to 0.6%), they all contain larger variations on individual benchmarks (ranging from 0.8% to 5.2%). Also, when looking at individual benchmarks, about 40 commits result in a variation of more than 1.0% (not ignoring reverts and relands).
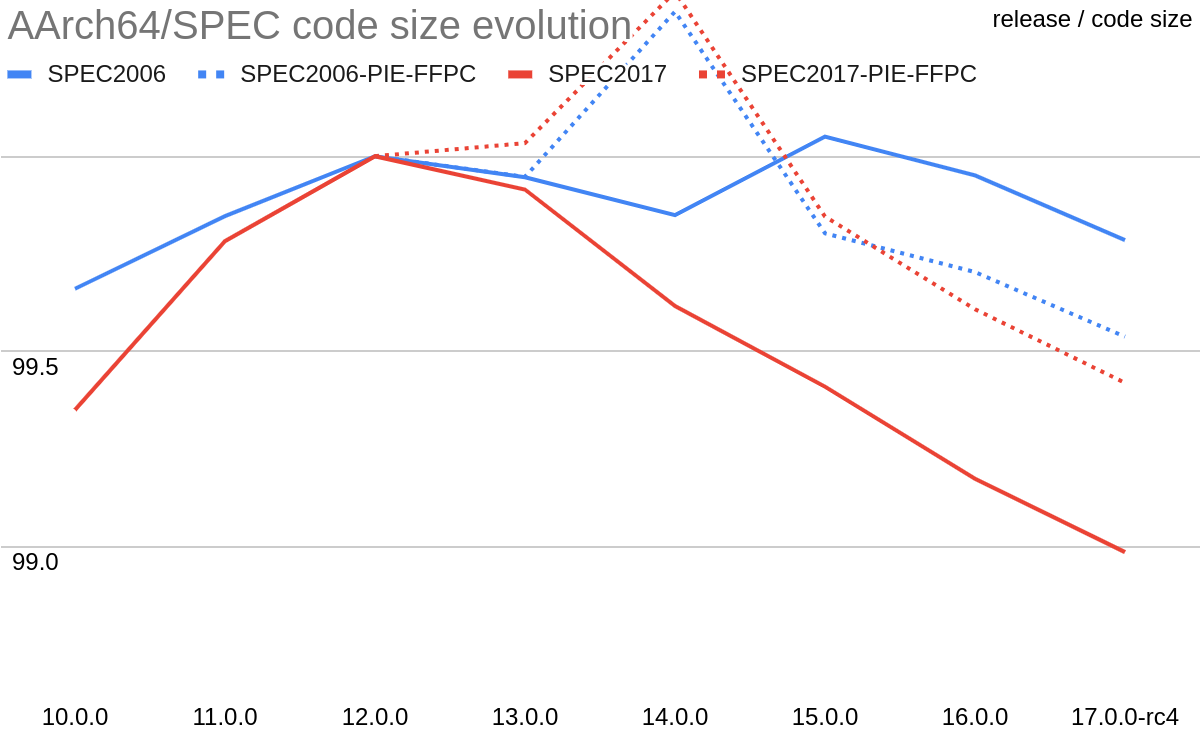
Figure 3: Evolution of code size - fixed (AArch64)
COMMITS IMPACTING -Oz CODE SIZE
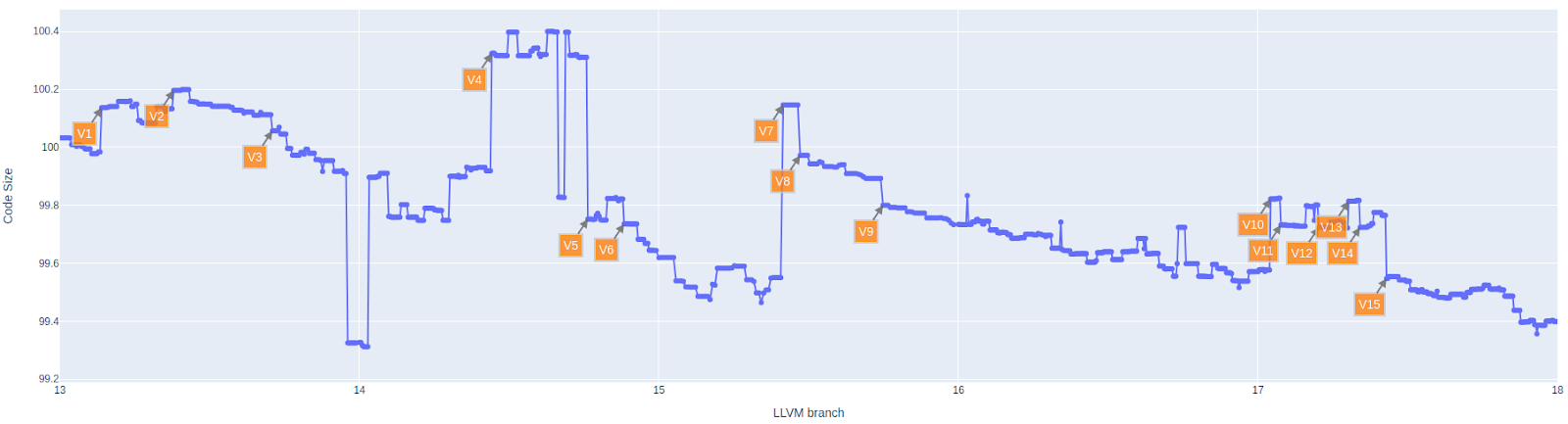
Figure 4: Commits impacting code size (AArch64)
V1 | +0.15% | [NFCI] SCEVExpander: emit intrinsics for integral {u,s}{min,max} SCEV expressions |
V2 | +0.06% | [SLP]Improve cost model for the vectorized extractelements. |
V3 | -0.06% | Return “[CGCall] Annotate\ |
V4 | +0.41% | [AArch64] Make -mcpu=generic schedule for an in-order core |
V5 | -0.56% | Making the code compliant to the documentation about Floating Point support default values for C/C++. |
V6 | -0.09% | [IRGen] Do not overwrite existing attributes in CGCall. |
V7 | +0.60% | Reland “[Driver] Default CLANG_DEFAULT_PIE_ON_LINUX to ON"" |
V8 | -0.17% | [AArch64] Split fuse-literals feature |
V9 | -0.09% | [MachineSink] replace MachineLoop with MachineCycle |
V10 | +0.25% | [MachineOutliner][AArch64] NFC: Split MBBs into “outlinable ranges” |
V11 | -0.09% | [MachineOutliner] Make getOutliningType partially target-independent |
V12 | -0.08% | [AArch64] Cost-model vector splat LD1Rs to avoid unprofitable SLP vectorisation |
V13 | +0.09% | [MachineOutliner] Fix label outlining regression introduced in D125072 |
V14 | -0.09% | [AggressiveInstCombine] Enable also for -O2 |
V15 | -0.22% | [AArch64] Combine SELECT_CC patterns that match smin(a,0) and smax(a,0) |
These are some of the biggest AArch64 code size variations on SPEC CPU (2006 & 2017) benchmarks since tag llvmorg-13-init, ignoring revert/reland commits.
One can observe that MachineOutliner (V10, V11, V13) and AArch64 target specific patches (V4, V8, V12, V15) represent almost half of these variations. The remaining commits are mostly about generic optimizations (like MachineSink or AggressiveInstCombine).
NEXT
Linaro TCWG is currently working on several other activities related to code size reduction for LLVM AArch64.
- Compiler benchmarking. TCWG also runs multiple other benchmarking jobs, which measure performance and code size generated by LLVM and GCC compilers on various benchmarks and configurations (targets and optimization levels) [11].
- Tracking of the AOSP code size. A Jenkins job is run regularly to measure the code size of the AOSP project. If a significant variation is detected (on the whole project or on a subset), the commits since the last build on the AOSP and LLVM repositories are bisected to identify the exact commit responsible for the variation. This should help avoid unexpected code size increases [12].
- Identification of compiler tuning opportunities. Experimentation with combinations of optimization flags and thresholds were performed on both AOSP project and SPEC benchmarks. Several optimization flags and thresholds beneficial to code size reduction compared to -Oz optimization level were identified. This could be used for compiler tuning (changing optimizations run by default or default threshold values), or simply for choosing different flags when building. For example, it has been shown that such combinations could lead to ~6% code size reduction on AOSP compared to -Oz [Figure 6]. Performances were also measured on benchmarks to show the impact on performances, even if not really important at -Oz level [Figure 5] [13]
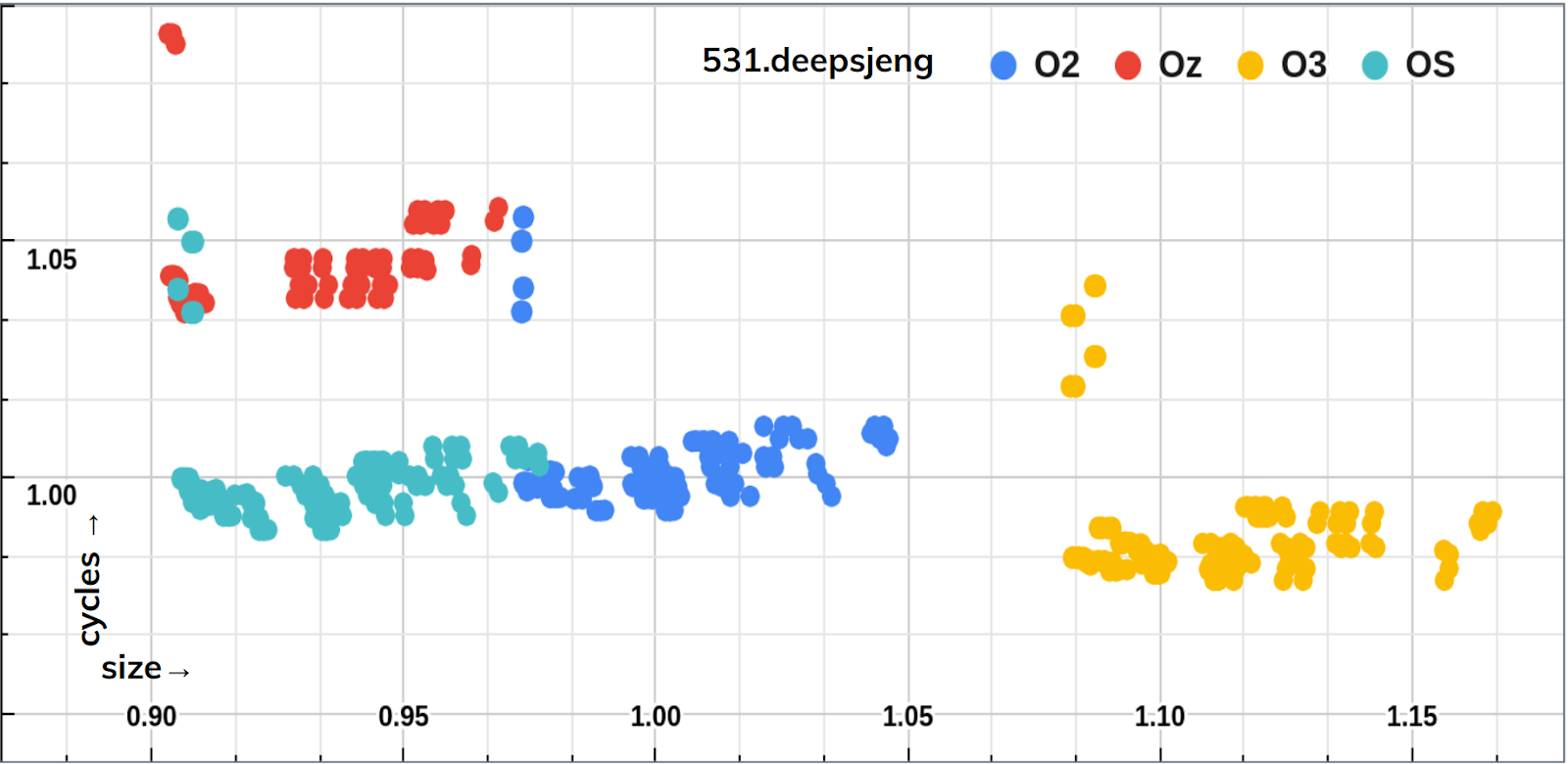
Figure 5: impact of inlining flags on deepsjeng
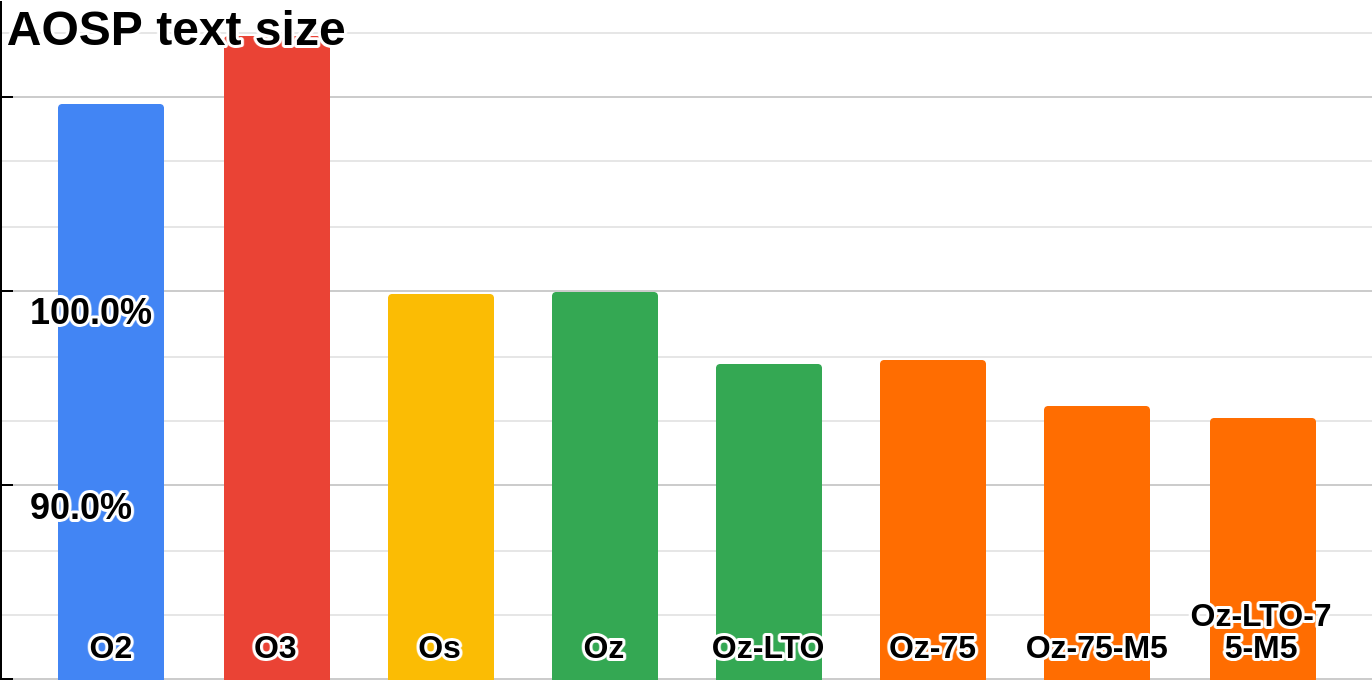
Figure 6: impact of optimization flags on AOSP
- Analysis of code size reduction opportunities using inlining optimization. Specifying a custom inlining threshold value could result in a code size reduction of more than 3% on AOSP compared to -Oz. On this project, tenths of objects are at least 2 times larger with -Oz than with -O2 due to a lower threshold in this level. While this still needs to be analysed, it at least shows that there may be room for interesting improvements here [Figure 7]. This may be an interesting topic for a future blog post.
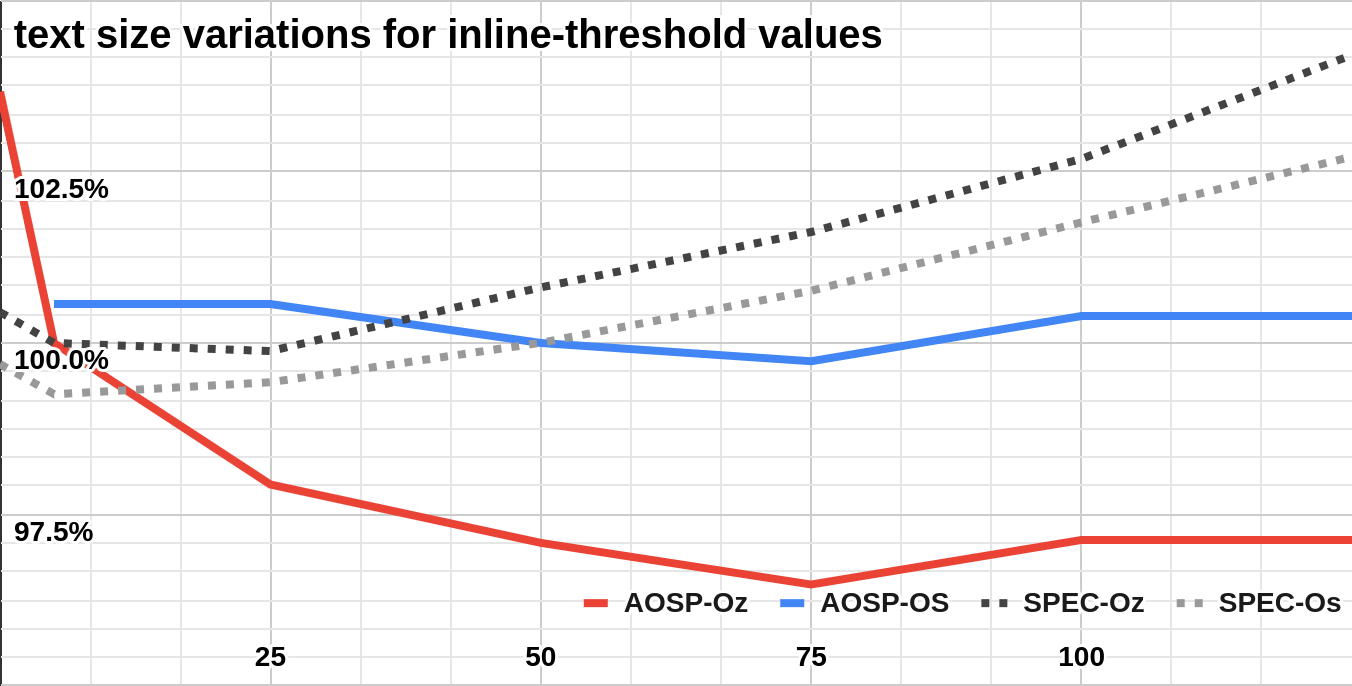
Figure 7: code size for inline-threshold values
For the LNT dashboard itself, the plan is to continue the tracking, adding measurements obtained with latest LLVM versions everyday. Measurement of performance and of code size generated with other optimization levels could also be added in the future.
For more information on Linaro’s work on toolchains and compilers, check out the project page here. You can also contact us at linaro-toolchain@lists.linaro.org.
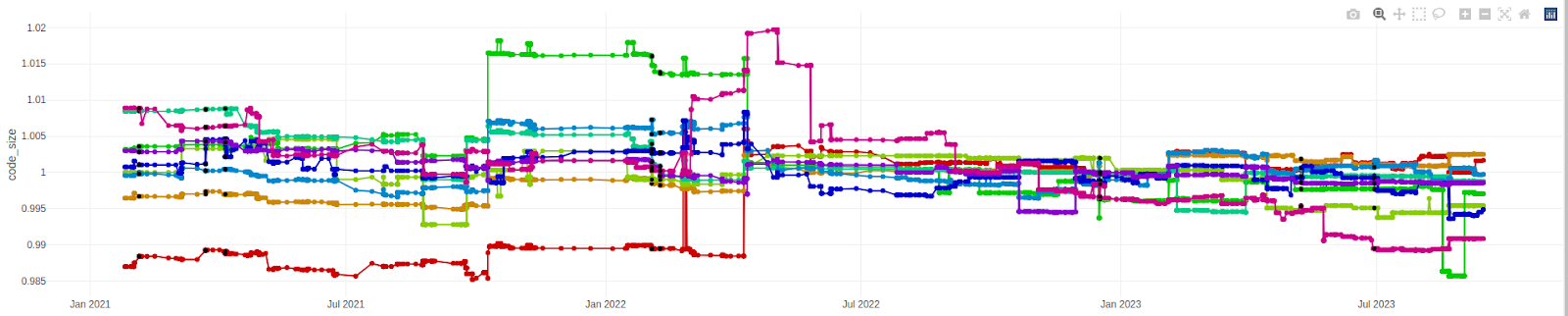
Figure 8: LNT dashboard [14]
REFERENCES
[1] Inlining for Code Size Reduction
[2] Uber Blog: How Uber Deals with Large iOS App Size, CGO21 paper
[3] 2022 LLVM Dev Mtg: Inlining for Size, paper
[4] 2022 LLVM Dev Mtg: Linker Code Size Optimization for Native Mobile Applications, paper
[5] Android Open Source Project https://source.android.com/
[6] The LLVM Compiler Infrastructure Project https://llvm.org/
[7] Standard Performance Evaluation Corporation https://www.spec.org
[8] Linaro LNT dashboard (WIP) http://llvm.validation.linaro.org:38000/
[9] https://ci.linaro.org/view/tcwg-all/job/tcwg-lnt-run-spec-codesize/
[10] LLVM LNT http://lnt.llvm.org/
[11] https://ci.linaro.org/view/tcwg_bmk/
[12] https://ci.linaro.org/view/tcwg_aosp/
[13] https://www.slideshare.net/linaroorg/bkk16308-the-tool-called-autotuned-optimization-system-atos