


As part of project Orko we have been busy improving the ecosystem of edge-computing. A fundamental part of that has been the infrastructure work to enable hypervisor agnostic virtio backends. Today we are giving a status update on our work in this area and discuss how the rust-vmm ecosystem helps us with our mission.
Introduction to Virtio
Virtio has standardized how paravirtualized guests talk with host devices. Instead of going down the stack to the very bottom where a device access is trapped and a physical device is faked, we switch at a higher level. Instead of trying to emulate a very specific piece of hardware, virtio provides a protocol for each type of device. The guest can then efficiently issue requests to a device without caring about the details of the backend implementation. This removes the need for hypervisor-specific drivers in the guest. Efficient shared-memory structures also reduce the number of context switches to the hypervisor. Overall this allows virtio to simplify both the guest and the hypervisor side while also providing great performance.
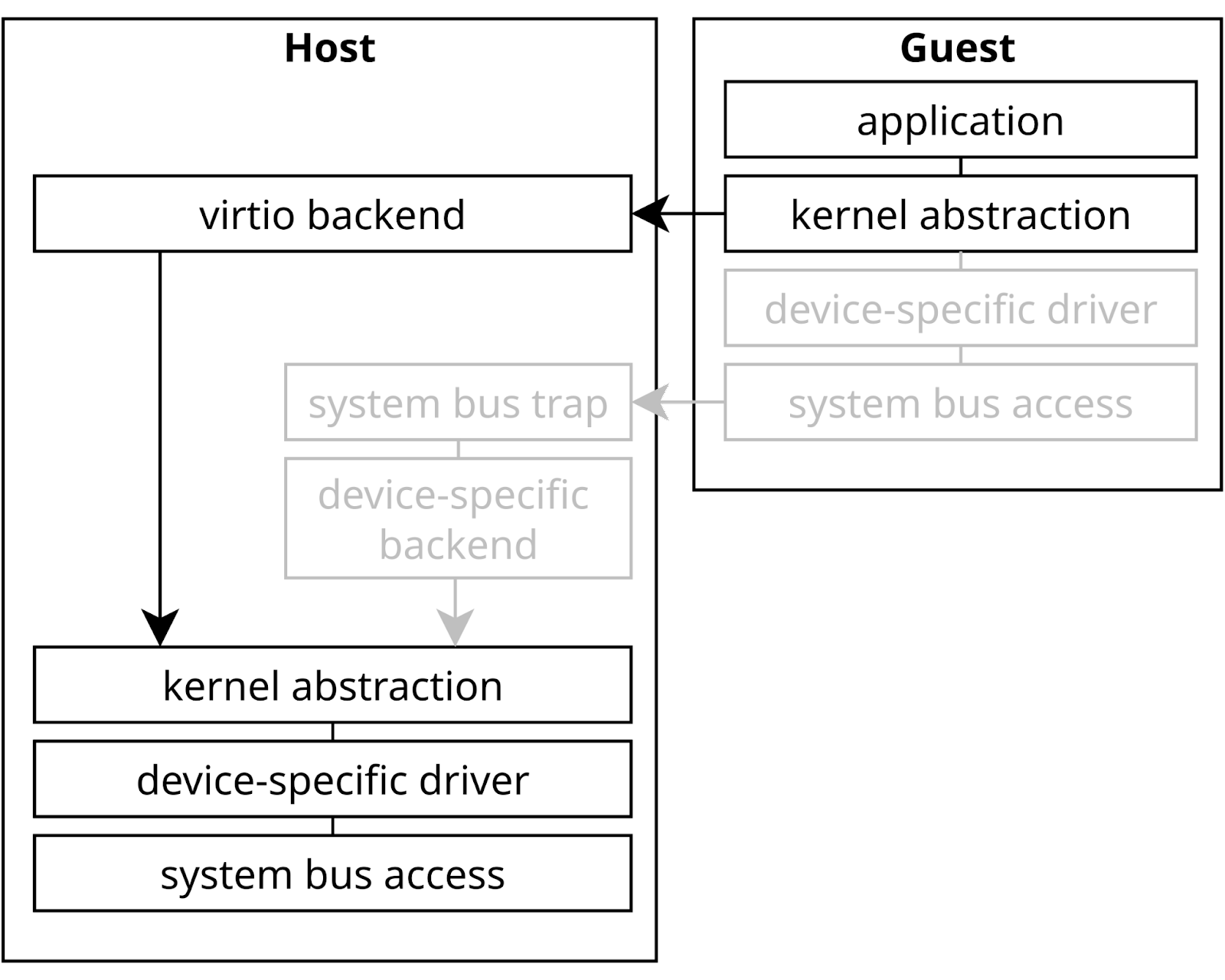
Figure 1: With the guest kernel coordinating, virtio allows to avoid frequent and costly traps on low-level system level. Instead, a generic virtio driver can efficiently transfer buffers to the virtio backend.
The missing edge
While most of today’s virtualization usage happens in traditional data-centers, single chips have become tremendously powerful in recent years. This provides significant computing resources in edge devices. A single chip now has enough head-room to handle multiple tasks. As an example, the automotive industry is challenged by increasingly software-heavy systems and is looking for ways to consolidate functionality onto fewer, more powerful devices. SOAFEE is an interest group that is looking to enable that using cloud-native technology.
Compared to traditional cloud setups, software on the edge typically will interface with a wider range of hardware. Storage and networking solutions have a very healthy virtio ecosystem due to the massively virtualized cloud infrastructure. But edge devices may also want to read that temperature sensor over I2C, steer a GPIO pin or run machine learning tasks on a video stream input. Typical solutions for this often involved pass-through of the specific hardware. This ties the VM to a hardware-specific solution which of course goes against the cloud spirit of abstracting away concrete hardware solutions. Linaro has been actively filling this gap by contributing towards virtio standards for protocols like I2C, GPIO or IOMMU.
Industrial or automotive use cases also frequently come with different requirements than those found in the cloud. A self-driving vehicle might impose stricter real-time and safety demands compared to a throughput-optimized server. Type-2 hypervisors depend on fairly complex operating system infrastructure to schedule domains. This makes it difficult to verify the freedom from interference of individual domains. Xen, especially in dom0less mode, offers a road towards simplifying that problem a lot. Instead of needing to reason about a full kernel and user-space that control VMs one can consider a much smaller core.
There is a problem though… while virtio standardizes the interface between the hypervisor and the guest, the compatibility of backends across hypervisors is less established.
Reusing vhost-user daemons across hypervisors
Today most hypervisors or cloud providers use virtio to some degree. But the actual implementation of the backend typically is hypervisor-specific. The control and data plane of the device were typically split in order to allow the data plane to interface with the guest without costly hypervisor mediation. The vhost protocol describes the coordination between the control and data plane happens. This allows offloading of data plane tasks to the host kernel, but it still requires a fairly tight coupling with the control plane that is tied to the hypervisor. Moving complex handling of untrusted, guest-controlled memory into the kernel may also be undesired from a security perspective.
vhost-user was modeled after vhost but allows offloading backend tasks to a user-space daemon. Yet, being replacements for data-plane only kernel modules, most vhost-user daemons still ended up being dependent on hypervisor-specific shims that make it difficult to reuse daemons. For example, QEMU’s vhost-user devices handle configuration and setup in the hypervisor and the backend daemon only does the data plane handling. Support for querying configuration and control data was eventually added to the specification, but the QEMU devices still follow the original vhost architecture where only the actual device emulation was offloaded to a separate process. This makes it hard to reuse these daemons for other hypervisors that lack these frontend stubs. Backends typically are expected to be configured in specific ways that are not particularly documented or standardized, breaking if their matching frontend stub is missing.
Ideally, a hypervisor would only need to implement one of the virtio transport mechanisms and simply forward control requests to the backends. We have been busy working on improving that situation. Progress has been made to support truly standalone vhost-user daemons and reduce the amount of boilerplate code in the frontends. The final step is to also query the actual device type from the backend. This would limit the configuration in the hypervisor to a simple list of backend sockets. The hypervisor can then treat every device class the same, regardless of the actual type.
We also started demonstrating this concept by proving vhost-device daemons working for both QEMU and Xen. By enabling Xen support for virtiofsd we also proved the concept on an independent, well-established daemon. Adding Xen support to this range of daemons was mostly enabled by adding support for Xen memory mappings to the core rust-vmm libs.
The virtio Rust ecosystem
As the name might suggest, rust-vmm is written in Rust. While user-space backends may run as unprivileged users and use sandboxing, virtual devices are still a prime target for attackers. Rust’s type and memory-safety guarantees as well as native speed make it a good choice here. rust-vmm was not first to identify this. crosvm came first as Google’s solution for securing Linux on Chromebooks and Android VMs. Firecracker started as a hypervisor for microVMs and Cloud Hypervisor followed while targeting general purpose VMs.
In order to allow collaboration across these projects, rust-vmm was founded. Initially starting off with bits from crosvm, rust-vmm components saw use as building blocks for Firecracker and Cloud Hypervisor. As universal, hypervisor agnostic building blocks, these components also were a perfect match for Linaro’s vision of reusable device backends. Today, we maintain a quickly growing number of backend daemons under the umbrella of the vhost-device repository.
As of today, that repository has daemons for GPIO, I2C, random number generators, SCMI, SCSI, VSOCK, sound and video devices. Virtiofsd, while developed outside of the rust-vmm umbrella, also is based on the same rust-vmm libraries as the vhost-device ones.
Outside of the rust-vmm ecosystem, crosvm also comes with a few additional virtio backends. However, these backends are built into the KVM-backed crosvm hypervisor and cannot easily be used in other setups. While some rust-vmm components originated in crosvm, rust-vmm exports them as reusable components. This allows hypervisors and vhost-user daemons to use the same building blocks without needing to reinvent the wheel.
This layered toolbox architecture helped us when adding Xen support by abstracting the required memory mapping logic away from the daemon. After adding Xen guest memory maps to vm-memory, Xen support for the entire rust-vmm ecosystem came “for free”. It also paves the way for more secure memory models where access is granted on page granularity instead of the entire guest memory. Eventually this will allow offloading device backends to other virtual machines that may be highly restricted in their access.
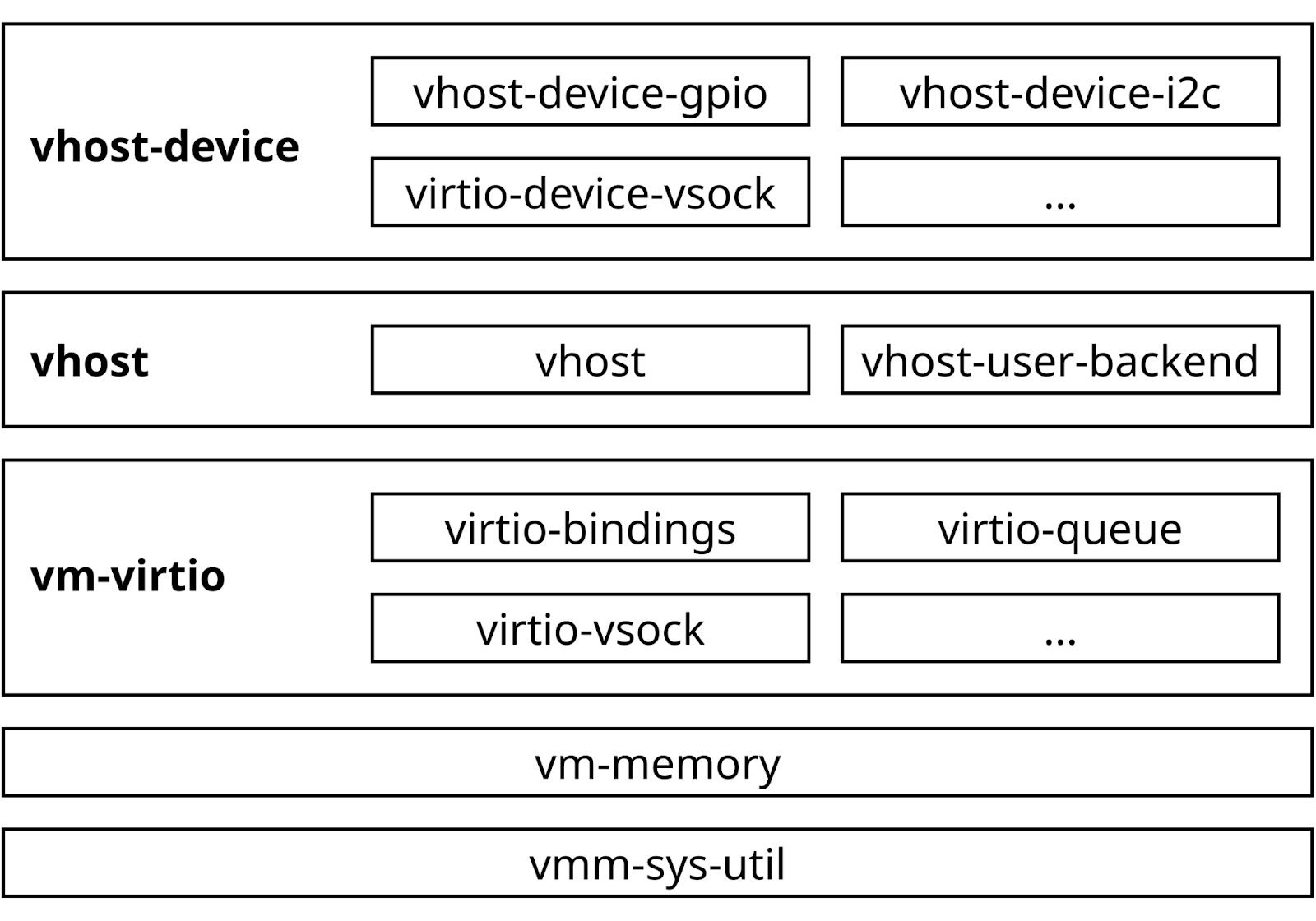
Figure 2: rust-vmm is organized into many crates that abstract individual aspects of virtualization. Of particular interest for us are vm-memory (abstraction of mmap’d guest memory), virtio-queue (tools for handling virtio descriptors) and vhost-user-backend (implementation of the vhost-user protocol). While the number of crates may be overwhelming at start, it allows you to pick and choose the tools needed for the particular task.
Overall, rust-vmm is maturing into a versatile and highly reusable ecosystem. The flexibility makes it a great choice to demonstrate new virtualization technologies and the rigorously tested Rust code base provides confidence in code and changes.
Outlook
Linaro is working towards showcasing all the newly developed features in a Demo during Connect 2024. We plan to demonstrate SOAFEE use-cases on top of our Trusted Reference Stack. Our roadmap and current work items can be viewed on our project page. If you are interested in collaborating feel free to say hello on #linaro-virtualization on libera.chat or checkout our other virtualization blog posts.