

Linaro’s Toolchain Working Group is working on compiler optimizations in GCC and this blog post is about our recent improvements to vector initialization for NEON, which benefits the auto-vectorizer as well as code written using NEON intrinsics.
What is vector initialization?
Put simply, vector initialization refers to filling up a vector register with scalar elements. GCC uses a number of tricks to efficiently initialize a vector depending on the nature of scalar elements.
For example:
#include <arm_neon.h>
int8x16_t f(int8_t x)
{
return (int8x16_t) { x, x, x, x, x, x, x, x,
x, x, x, x, x, x, x, x };
}In this case, the compiler detects that all the elements used to initialize the vector are the same, and it can thus use a single dup instruction to fill up the vector:
Another example:
#include <arm_neon.h>
int8x16_t foo()
{
return (int8x16_t) { 0, 1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15 };
}In this case, the compiler detects that we are loading all constants, and thus it uses a constant pool to store all the constants and uses adrp+ldr to fill up the vector:
foo:
adrp x0, .LC0
ldr q0, [x0, #:lo12:.LC0]
ret.LC0 is the address of the constant pool that stores the above constants (not shown in the code-gen). While these tricks work well in isolation, they however produce suboptimal code-gen when combined together.
For example:
#include <arm_neon.h>
int8x16_t foo(int8_t x)
{
return (int8x16_t) { x, 0, x, 1, x, 2, x, 3,
x, 4, x, 5, x, 6, x, 7 };
}results in following code-gen:
foo:
adrp x1, .LC0
ldr q0, [x1, #:lo12:.LC0]
ins v0.b[0], w0
ins v0.b[2], w0
ins v0.b[4], w0
ins v0.b[6], w0
ins v0.b[8], w0
ins v0.b[10], w0
ins v0.b[12], w0
ins v0.b[14], w0
retUsing divide and conquer strategy
We could do better for the above case, by recursively initializing even and odd parts of the sequence and combining them with zip1 instruction. A pseudo code to represent the above would be:
v_even = { x, x, x, x, x, x, x, x };
v_odd = { 0, 1, 2, 3, 4, 5, 6, 7 };
v_res = zip1 v_even, v_odd;Note that v_even and v_odd contain only 8 elements, as opposed to 16 in v_res, so the type of v_even and v_odd would be int16x8_t, rather than int8x16_t. For this purpose, we stop recursing when v_res is 64 bits (since we don’t support 32-bit vectors on aarch64).
With this approach, the code-gen becomes:
foo:
dup v31.8b, w0
adrp x0, .LC0
ldr d0, [x0, #:lo12:.LC0]
zip1 v0.16b, v31.16b, v0.16b
retThe compiler loads ‘x’ (represented by w0), into v31.8b (v_even) and the constants in d0 (v_odd). The result of interleaving the vectors is then combined with zip1.
For some terminology, let’s call the code-gen without using divide and conquer approach as “fallback sequence”. The same approach is eventually used by the divide and conquer approach after we cannot divide the initializer sequence into more halves.
In some cases, the divide-and-conquer approach may result in longer code-gen sequences compared to the fallback version, but may actually be faster since both halves are independent and can thus take advantage of instruction-level parallelism.
For example:
#include <arm_neon.h>
int16x8_t f_s16 (int16_t x0, int16_t x1, int16_t x2, int16_t x3,
int16_t x4, int16_t x5, int16_t x6, int16_t x7)
{
return (int16x8_t) { x0, x1, x2, x3, x4, x5, x6, x7 };
}Fallback code-gen sequence:
f_s16:
sxth w0, w0
fmov s0, w0
ins v0.h[1], w1
ins v0.h[2], w2
ins v0.h[3], w3
ins v0.h[4], w4
ins v0.h[5], w5
ins v0.h[6], w6
ins v0.h[7], w7
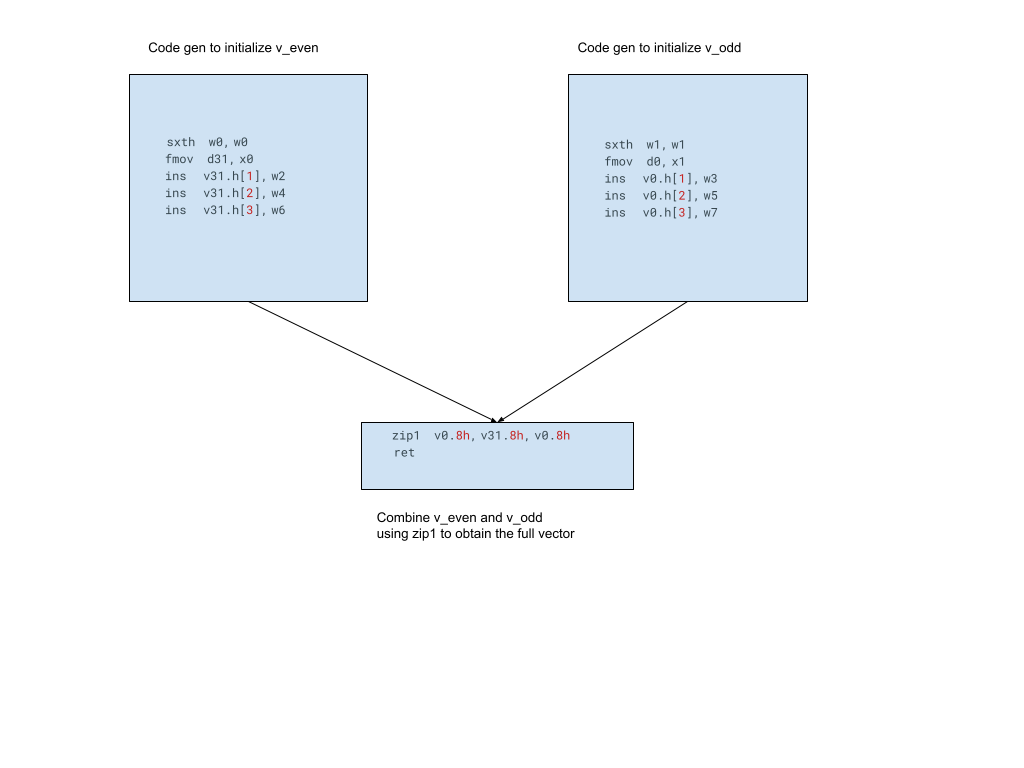
retDivide and conquer code-gen sequence:
f_s16:
sxth w0, w0
sxth w1, w1
fmov d31, x0
fmov d0, x1
ins v31.h[1], w2
ins v0.h[1], w3
ins v31.h[2], w4
ins v0.h[2], w5
ins v31.h[3], w6
ins v0.h[3], w7
zip1 v0.8h, v31.8h, v0.8h
ret
While the fallback sequence is shorter, each successive ins instruction has dependency on previous one (because it has to update v0 from previous ins along with setting the vector lane), which forces the entire sequence to execute serially. With the divide and conquer approach the code-gen for initializing respective halves is interleaved and can thus be parallelized as illustrated in the diagram below:
Note that this strategy may not always be optimal. For example:
#include <arm_neon.h>
int8x16_t f_s8(int8_t x, int8_t y)
{
return (int8x16_t) { x, y, 1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14 };
}Fallback code-gen sequence:
f_s8:
adrp x2, .LC0
ldr q0, [x2, #:lo12:.LC0]
ins v0.b[0], w0
ins v0.b[1], w1
retCode-gen sequence with divide and conquer approach:
f_s8:
adrp x2, .LC0
ldr d31, [x2, #:lo12:.LC0]
adrp x2, .LC1
ldr d0, [x2, #:lo12:.LC1]
ins v31.b[0], w0
ins v0.b[0], w1
zip1 v0.16b, v31.16b, v0.16b
retIn this case we generate code recursively for the following halves { x, 1, 3, 5, 7, 9, 11, 13 } and { y, 2, 4, 6, 8, 10, 12, 14 } and combine the result with zip1, which is less efficient than fallback code-gen, which simply loads the constants from the constant pool and uses two ins instructions for inserting ‘x’ and ‘y’ respectively.
Since we do not know beforehand if the divide and conquer strategy will result in better code-gen compared to fallback version, we generate code sequences using both approaches and compare the cost of each sequence and the one with lesser cost wins.
Single constant case
Consider the following example where the initializer contains all the same elements except for a single constant:
#include <arm_neon.h>
int8x16_t f_s8(int8_t x)
{
return (int8x16_t) { x, x, x, x, x, x, x, x,
x, x, x, x, x, x, x, 1 };
}Code-gen:
f_s8:
movi v0.16b, 0x1
ins v0.b[0], w0
ins v0.b[1], w0
ins v0.b[2], w0
ins v0.b[3], w0
ins v0.b[4], w0
ins v0.b[5], w0
ins v0.b[6], w0
ins v0.b[7], w0
ins v0.b[8], w0
ins v0.b[9], w0
ins v0.b[10], w0
ins v0.b[11], w0
ins v0.b[12], w0
ins v0.b[13], w0
ins v0.b[14], w0
retWhich is pretty verbose because gcc used a heuristic to load a constant first and then insert the rest of the elements. The heuristic has been tweaked in 9eb757d11746c006c044ff45538b956be7f5859c so that only if a single constant element is found, the vector is filled with the same element using dup and the single constant is instead inserted into the vector. The resulting code-gen sequence thus becomes:
f_s8:
dup v0.16b, w0
movi v31.8b, 0x1
ins v0.b[15], v31.b[0]
retWhile this is unconditionally a win for a single constant, extending to multiple constants (or repeated instances of a same constant) gets trickier with more complicated trade-offs, and is thus not implemented currently. The above divide and conquer approach also may help to address the issue partially in case of multiple constants, for instance, if one-half of the vector can be initialized using dup.
Using xzr register to insert 0s
Consider the following contrived test case:
#include <arm_neon.h>
int8x16_t foo(int8x16_t v)
{
v[1] = 0;
return v;
}Code-gen:
foo:
movi v31.2s, 0
ins v0.b[1], v31.b[0]
retThe movi instruction in code above is redundant since we can use wzr/xzr for assigning 0:
foo:
ins v0.b[1], wzr
retWhile it’s a modest improvement, it saves one register, which might make a difference for larger programs, especially in regions having high register pressure like loops.
Summary
Vector initialization is a pretty common operation expressed either via intrinsics or created by auto-vectorizer. This blog discussed improvements to NEON vector initialization, using a new divide and conquer approach, which involved significant changes to aarch64_expand_vector_init. During GCC bootstrap on AArch64, we observed a couple of places for auto-generated code which benefits from the divide and conquer approach and will likely extend to other programs that make heavy use of vector operations.
In the future, we plan to address more cases where vector initialization is sub-optimal like:
- PR111697: Improve code-gen for initializing vector with a loop.
- Improving heuristics to extend the single constant case described above to multiple constants.
- Use a combination of dup+vext for initialization sequence consisting of two variables where one follows the other like
{ x, x, x, x, y, y, y, y } - And more as we find them :)
(Digression – An interesting experiment IMO would be to use super-optimization to find optimal code sequences for common cases of vector initialization and possibly implement them in the compiler.)