


Running machine learning workloads on an embedded SoC with a mid-range CPU with good performance and power management is a challenge. Many SoCs have included integrated NPUs (Neural Processing Units) to accelerate on-device machine learning performance. Software support for NPUs is often proprietary and open source support, when it exists, can be very limited.
Arm’s range of NPUs starting with the Ethos-U55 originally targeted microcontroller (Cortex-M) CPU acceleration. Its successor, the Ethos-U65, broadened this to being directly accessible to both Cortex-A and Cortex-R processors without passing through a Cortex-M intermediary (“Assisted Mode”). In this mode the NPU communicated with the Linux kernel on the host via remoteproc and the Cortex-M CPU.
Recently patches were merged in the Linux kernel and mesa, allowing the NPU to be accessed directly by the Cortex-A host and integrated directly into TensorFlow Lite and the kernel.
We wanted to answer a few simple questions based on this new direct kernel support.
- Can the NPU be used on real hardware with an open-source stack?
- Which models actually run on it?
- And what kind of speedup do we see compared to CPU execution?
This post will show what we found to be working, what does not yet work, and the performance numbers we measured on i.MX93.
Hardware Platform
All testing Was done on a ADLINK I-Pi OSM IMX93 development kit using the ADLINK OSM-IMX93 module. The system is based on the NXP i.MX93 SoC with dual Cortex-A55 cores, a Cortex-M33, and an Arm Ethos-U65 NPU.
Kernel Choice
For this work, we used Linux kernel version 6.19-rc1 as the base. The kernel was built from the mainline kernel v6.19-rc1, which includes the Ethos-U NPU support patches. These patches are required to expose the NPU device on i.MX93 as an accelerator.
Inference uses TensorFlow Lite together with Mesa’s Teflon delegate in direct mode.This is currently the only supported way to run workloads on the Ethos-U65. Supported operators are routed through Mesa and executed on the Ethos-U65. Operators that are not supported fall back to CPU execution.
Model Constraints
The Ethos-U65 is strict about model quantization. Models must be quantized to INT8 or UINT8 and use per-tensor quantization. Per-channel quantized models often fall back to CPU. Float models do not run on the NPU.
Because fallback happens silently, models need to be checked carefully to confirm that work is actually offloaded.
Performance results
All measurements were done using real TensorFlow Lite models. We did not use synthetic benchmarks.
Image classification
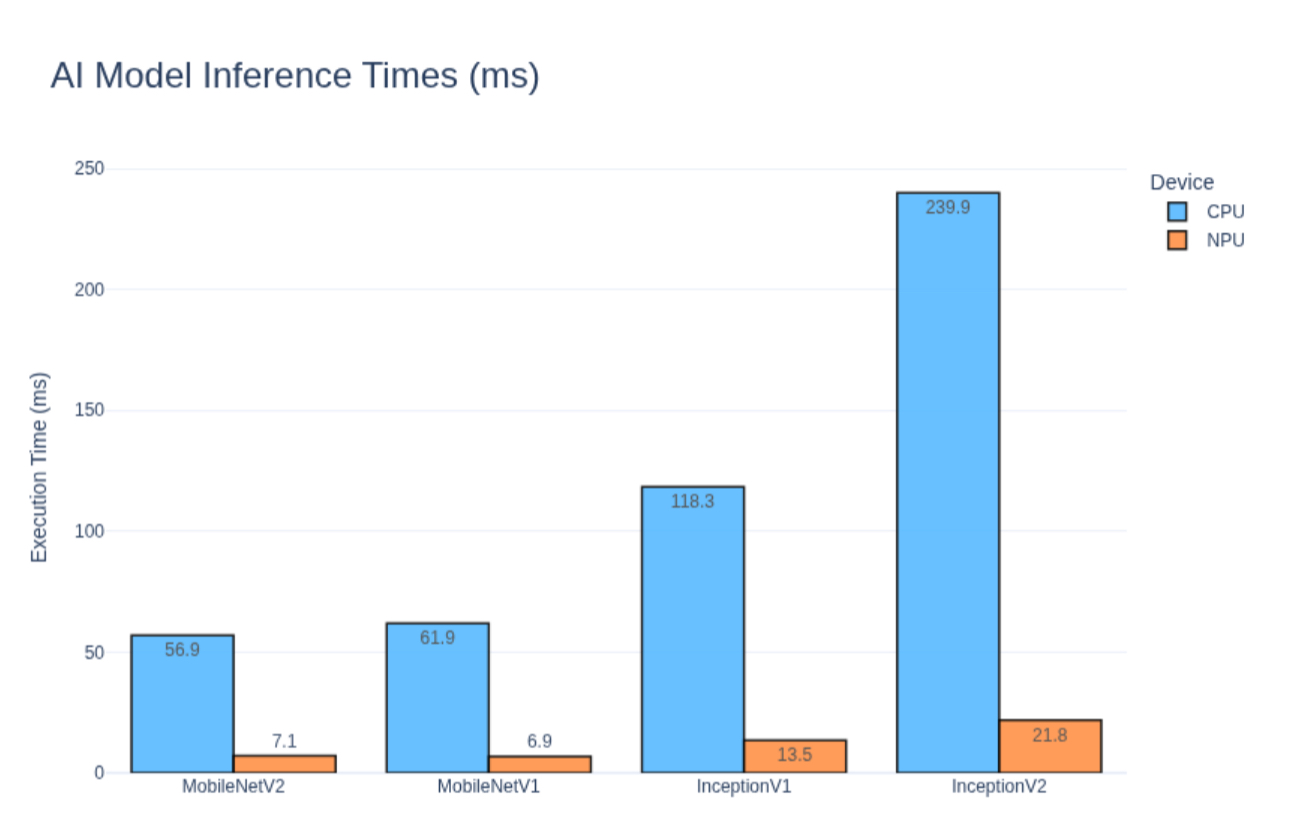
The diagram above highlights a clear pattern across the tested classification models. Inception V1 shows the largest relative speed up when moving from CPU to NPU execution, while MobileNet V1 achieved the highest absolute frame rate on the NPU.
MobileNet V2 and Inception V2 fall between these two extremes, offering a trade-off between latency and speedup. Across these models, we did not observe any difference in prediction accuracy between CPU and NPU execution. The outputs were consistent for the tested inputs.
Taken together, the diagram shows that different models benefit from NPU offloading in different ways: Inception V1 maximizes relative speedup compared to CPU, while MobileNet V1 achieves the lowest absolute latency and highest frame rate on the NPU.
Object detection
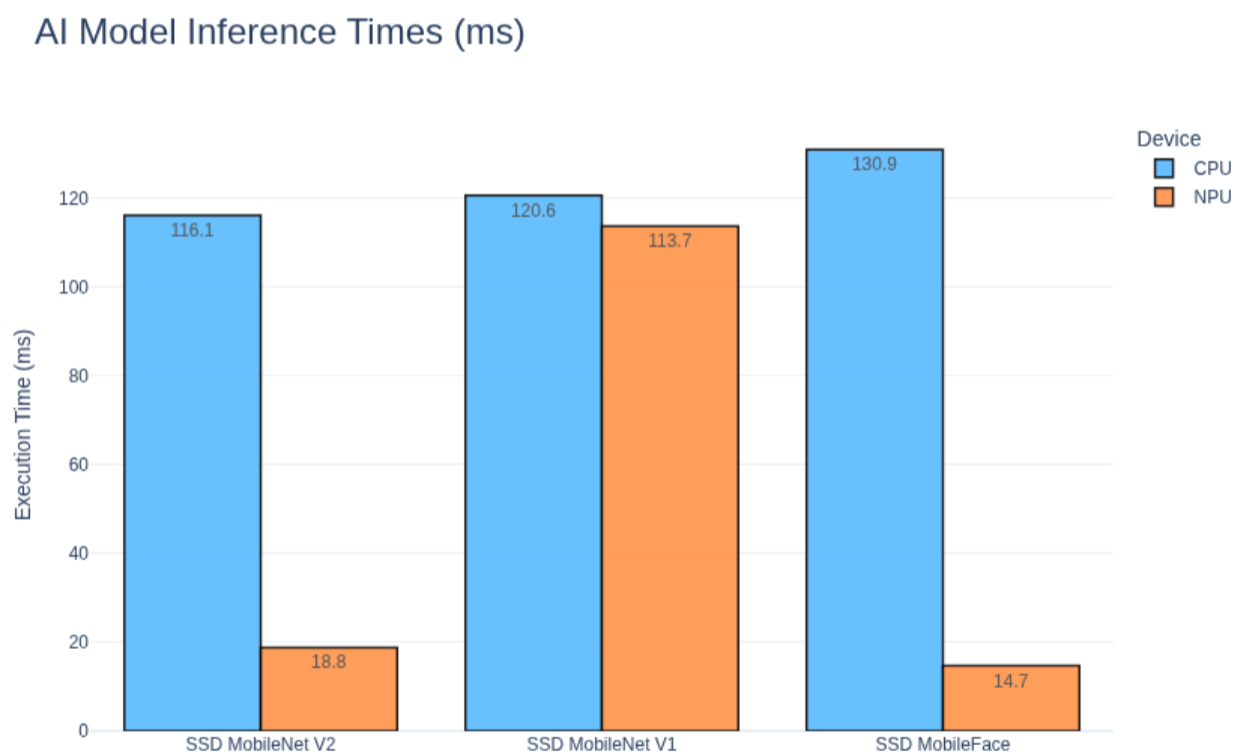
SSD MobileNet V2 is the only object detection model that works reliably on the NPU and provides a clear performance benefit. SSD MobileNet V1 can execute on the NPU, but the results are misleading. Latency is close to CPU execution and the model produces incorrect detections, which makes it impractical to use in its current form. This happens because MobileNet V1 falls back to the CPU a lot.
Other detection models either fall back to CPU execution, return incorrect output, or are too slow to be useful in practice.
CPU Baseline
For INT8 and UINT8 models, TensorFlow Lite does not use XNNPACK on the CPU. Instead, it relies on ruy and gemmlowp, which provide optimized integer kernels using ARM NEON. XNNPACK mainly targets floating-point workloads and is therefore not involved in the CPU execution path for these quantized models. This means the CPU baseline is already well optimized, and the observed NPU speedups reflect real hardware acceleration rather than a weak CPU backend.
Conclusions
At this stage, Ethos-U65 execution on i.MX93 works and delivers speedups between 6× and 11× for supported models, using a fully open-source stack.
Feedback and What’s next
If you have a similar or different experience with running inference directly from the kernel using the U65 using the latest patches, we’d be happy to hear from you. Please get in touch! In Linaro we care deeply about the status of the open source support for Arm hardware and we’re interested to hear from the community. We also offer consultancy on performance tuning for the Arm architecture and managing open source abstractions for hardware features.
We plan a follow-up post that will document the full setup in more detail to reproduce these results on the same hardware.