


Introduction
LLVM’s Fortran compiler, Flang, is currently under active development and Linaro Toolchain Working Group (TCWG) is a significant contributor to these efforts. We have fixed many bugs in Flang, improved compile time of large array constants and have more developments in progress. Flang is still not considered production-ready, but how does it compare with other Fortran compilers? This blog post provides an overview of this issue, focusing on performance.
Test setup
Before listing the compilers used in the performance tests, it’s important to know that Flang is often referred to as “LLVM Flang” to differentiate itself from “Classic Flang” - these are two separate and independent Fortran compilers. Classic Flang is an out-of-tree Fortran compiler targeting LLVM. It is an open-sourced version of pgfortran, a commercial Fortran compiler from PGI/NVIDIA.
The compilers selected for this comparison were:
- Classic Flang 15, from master branch [1], while it still used LLVM 15 by default [2].
- Classic Flang 16, from master branch [3], with LLVM 16 [4].
- LLVM Flang 16.0.6 [5].
- LLVM Flang, from main branch [6].
- Gfortran 13.2 [7].
Together with Classic Flang and LLVM Flang, Clang was used to build the benchmarks that used C and C++. For Gfortran, GCC (GNU Compiler Collection) was used instead.
To compare the performance of these toolchains, the set of benchmarks from SPEC (Standard Performance Evaluation Corporation) CPU 2017 was used. Note that the benchmarking process did not follow SPEC’s guidelines and therefore is not suitable for public reporting and/or submission to SPEC. That’s mainly because the benchmarks executed for each toolchain used a single iteration only, to save time.
The benchmarks were run using Linaro TCWG’s automated benchmarking infrastructure on a pool of Fujitsu FX700 HPC servers. These are AArch64 machines, with 48 cores running at 1.8GHz, 32GB of RAM (Random Access Memory) and NVMe (Non-Volatile Memory Express) storage. Each run of SPEC was distributed among 3 identical FX700 machines, running Ubuntu 22.04 LTS.
SPEC’s C, C++ and Fortran sources were all built with the -O3 optimization flag. Regarding NUMA control, the benchmarks were taskset to cores 36-47, NUMA node 3.
Results
Unlike LLVM Flang and Gfortran, Classic Flang failed to build the 507.cactuBSSN_r benchmark and produced incorrect results for 521.wrf_r, so these benchmarks were omitted in speedup graphs and were also excluded when calculating the geometric mean. This means that, at least with regards to SPEC 2017, LLVM Flang is already more compliant than Classic Flang now.
Figure 1 and Figure 2 show the execution time of the benchmarks, in seconds, for each compiler. Smaller bars are better.
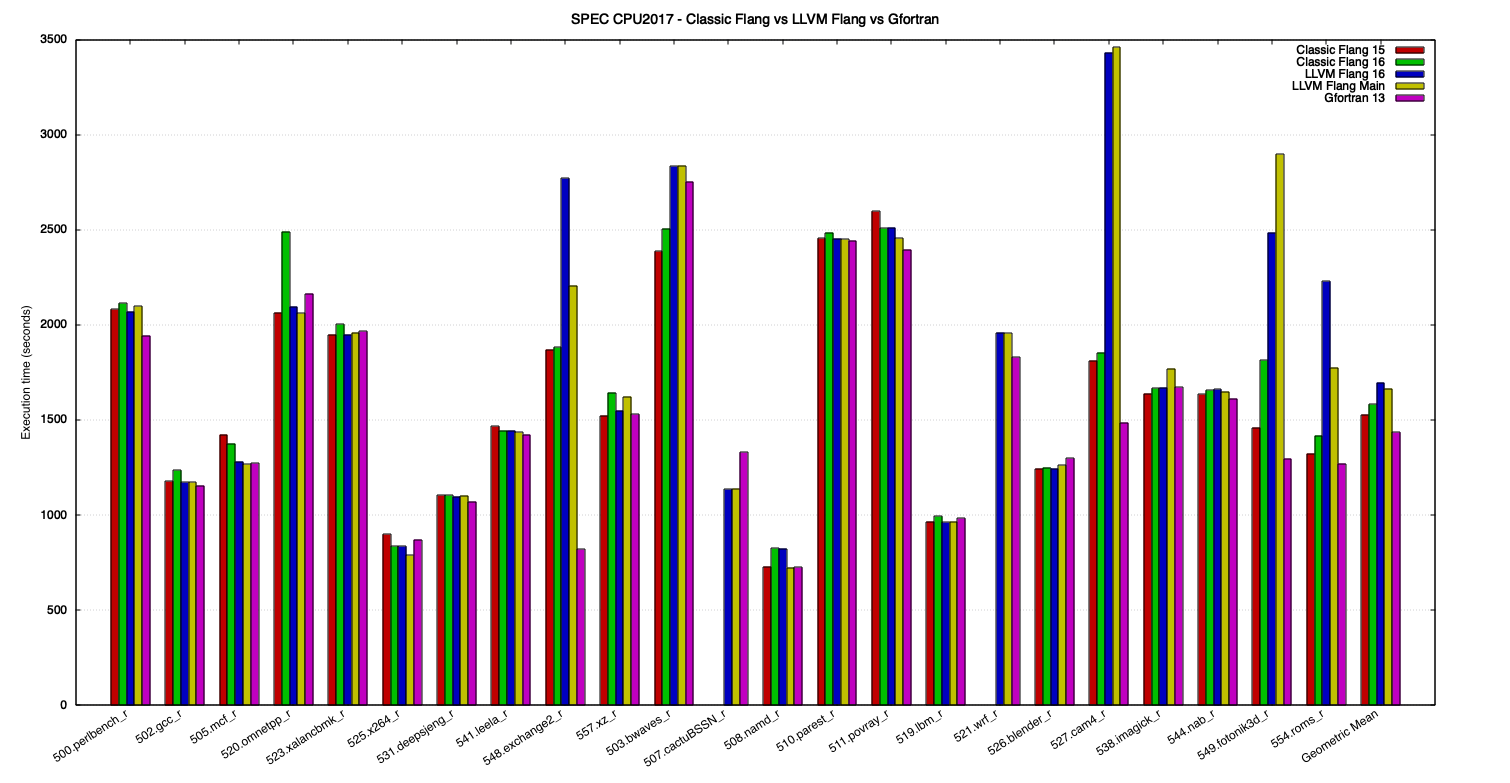
Figure 1: SPEC CPU 2017 execution times, for all benchmarks.
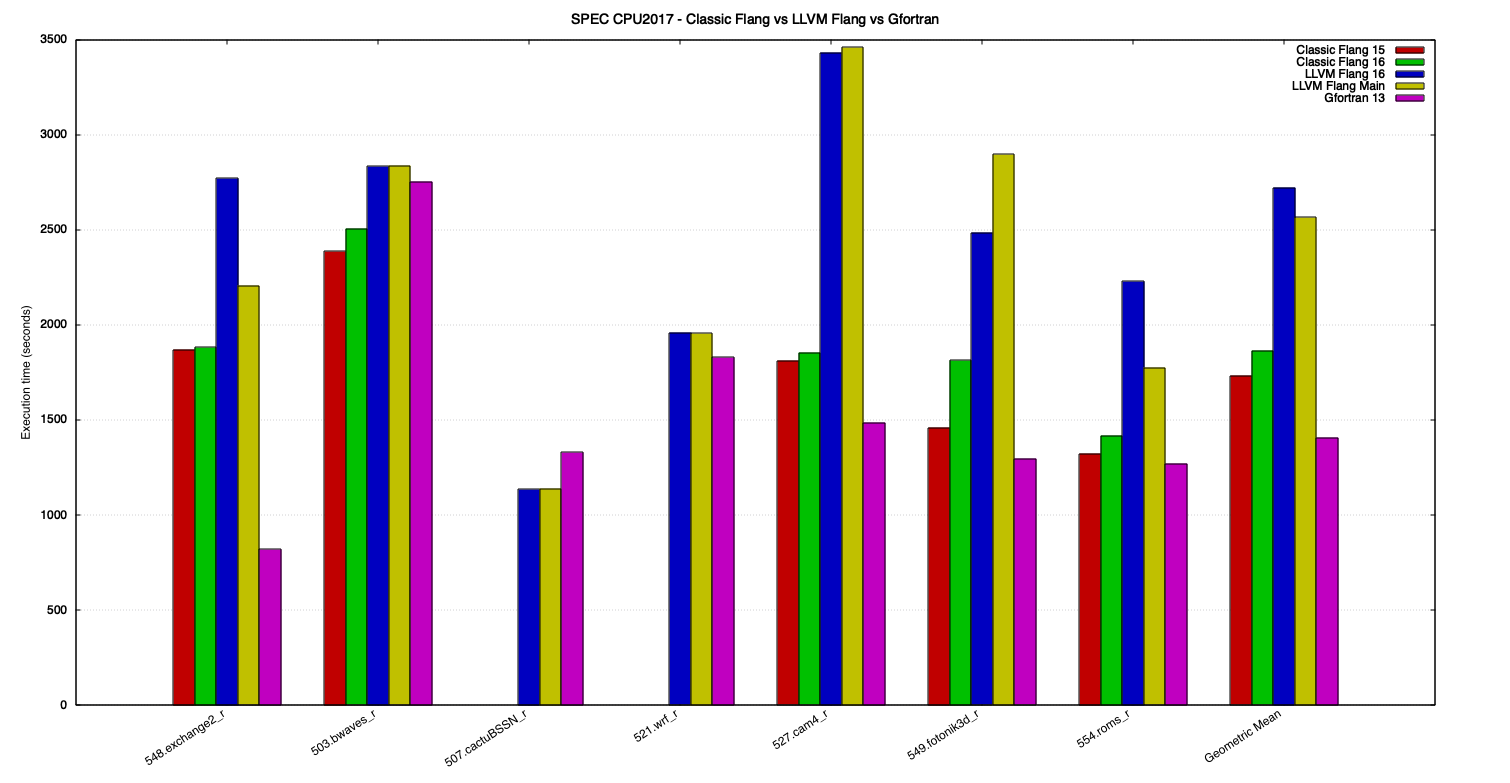
Figure 2: SPEC CPU 2017 execution times, for Fortran benchmarks.
Figure 3 and Figure 4 show the speedup of the benchmarks, relative to Classic Flang 15, for each compiler.
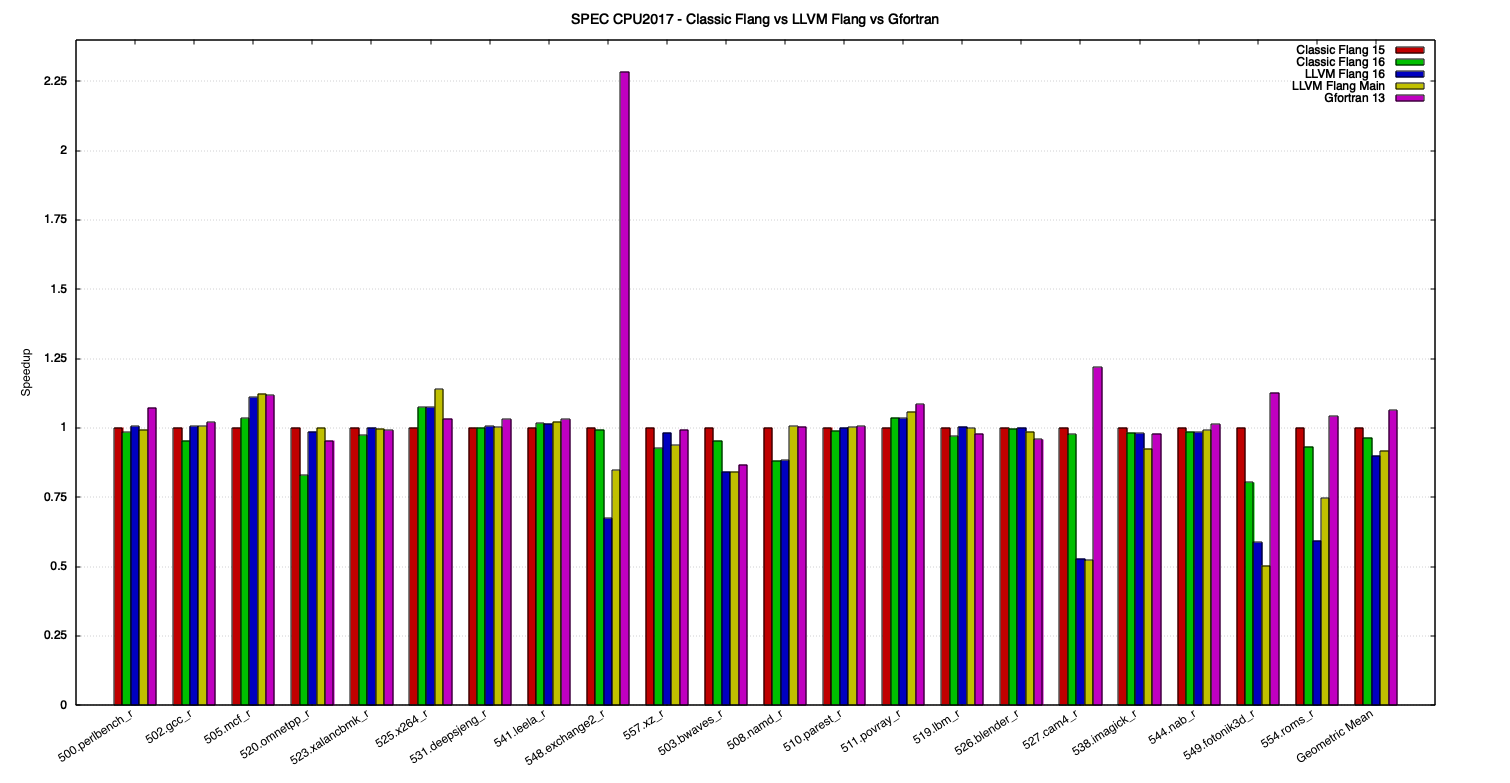
Figure 3: SPEC CPU 2017 speedups, for all benchmarks.
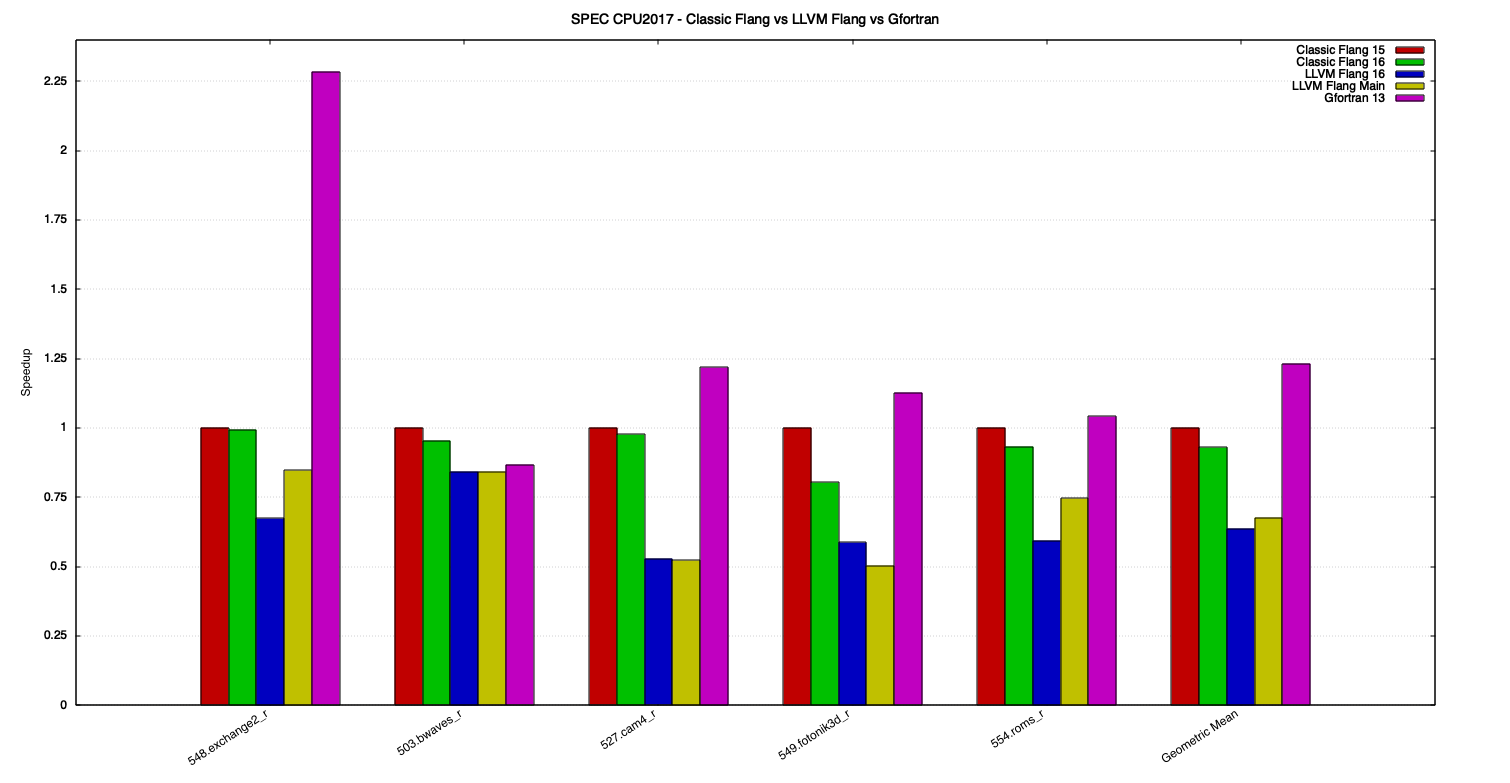
Figure 4: SPEC CPU 2017 speedups, for Fortran benchmarks.
In the previous graphs, it can be seen that the performance of benchmarks that don’t use Fortran are, in most cases, pretty close between the compilers. In benchmarks using Fortran, however, the variation is much higher. This shows the main performance differences between the tested toolchains reside in their Fortran frontends and not on backend optimizations, that are applied after the source code is lowered to intermediate representation.
521.wrf_r and 527.cam4_r benchmarks also use C besides Fortran while 507.cactuBSSN_r is composed of Fortran, C and C++ source files [10]. Because of the similar C and C++ performance of the compared toolchains, the differences seen in those multi-language benchmarks are most likely related to the Fortran part.
Among the benchmark results, the one that draws the most attention is 548.exchange2_r, where Gfortran is over 2 times faster than Classic Flang and LLVM Flang. In 527.cam4_r, 549.fotonik3d_r and 554.roms_r LLVM Flang’s performance is considerably worse than that of Classic Flang and Gfortran, where they are twice as fast in the worst cases. In 503.bwaves_r, however, LLVM Flang’s performance is pretty close to that of Gfortran and just a bit worse than Classic Flang.
The geometric mean of Fortran benchmarks shows that LLVM Flang is about 48% slower than Classic Flang, that is overall 23% slower than Gfortran. However, it’s important to remember that benchmarks 521.wrf_r and 507.cactuBSSN_r were excluded from the geometric mean, because Classic Flang couldn’t compile the latter and produced wrong results for the former. Just by being able to compile and run those correctly is already a big advantage of LLVM Flang over Classic Flang, but it also manages to perform just a bit worse than Gfortran on the first and better than it on the second.
Conclusion
LLVM Flang’s performance is not yet at the same level as that of Classic Flang and Gfortran, which was expected, given it is still not ready. But it’s good to see that LLVM Flang is already able to compile and run correctly all of SPEC CPU 2017 benchmarks. Regarding its performance, it’s about 48% slower than Classic Flang overall and no more than 2 times slower than it in the worst case. It’s still a considerable difference, but LLVM Flang’s developers have been actively working on improving the compiler’s performance, as well as standards support, compatibility with other Fortran software and bug fixes.
HLFIR (High Level Fortran Intermediate Representation) is among the current efforts to improve LLVM Flang. It makes it easier to implement support for some features of Fortran standard and also to write optimizations that require a higher level view of the compiled program. It should replace the FIR-only (Fortran Intermediate Representation) mode of lowering Fortran code to IR (Intermediate Representation) soon, which is currently being used [8].
Besides that, support for OpenMP 1.1 [9] is also almost complete and support for OpenACC is being added at a fast pace. There is still some way to go for LLVM Flang to reach production-ready status, but it looks like the end of the road is not that far off.
To find more information about Linaro’s work on LLVM Flang, see Flang Support in LLVM. To get involved and contribute with the Flang Project, check Getting Involved. Finally, if you want to get in touch with the Linaro Toolchain Working Group, or are interested in working with us to accelerate the development of Flang, don’t hesitate to reach out on our public mailing list linaro-toolchain@lists.linaro.org or privately via support@linaro.org .
References
- Flang Compiler, Classic Flang, 2023-07-04, 15, commit bbf70eeb727a15a6959276b77212e8a106fa7908, https://github.com/flang-compiler/flang.
- Flang Compiler, Classic Flang LLVM, 2023-04-19, 15.0.3, commit cd736e11b188a8f6ff14041abd818ad86f36b9bb https://github.com/flang-compiler/classic-flang-llvm-project/tree/release_15x.
- Flang Compiler, Classic Flang, 2023-07-26, 16, commit 1c99a086e0f3c1a2155fba1aa695022e5cce6d97, https://github.com/flang-compiler/flang.
- Flang Compiler, Classic Flang LLVM, 2023-07-11, 16.0.4, commit 5c04f282bab1b2e24c3eccab15fe9ff6be7c8f62, https://github.com/flang-compiler/classic-flang-llvm-project.
- LLVM, LLVM, 16.0.6, https://github.com/llvm/llvm-project/releases/tag/llvmorg-16.0.6.
- LLVM, LLVM Flang, 2023-07-28, 18.0.0, commit e4777dc4b9cb371971523cc603e1b8a5c7255e7e, https://github.com/llvm/llvm-project/tree/main/flang.
- GNU, GCC, 13.2, https://ftp.gnu.org/gnu/gcc/gcc-13.2.0.
- LLVM Discourse, [RFC] Enabling the HLFIR lowering by default, 2023-08-22, https://discourse.llvm.org/t/rfc-enabling-the-hlfir-lowering-by-default/72778.