

I/O control is the most powerful Linux solution for guaranteeing bandwidths with storage; but the most used I/O-control mechanism, throttling, can waste up to 80% of the storage speed, and fails to provide target guarantees with some common workloads (full details here IO-control-issues).
So, how do providers of production-quality services currently guarantee bandwidth to clients, containers, virtual machines and so on? Do they use also alternative solutions (to throttling)? If so, do these alternatives reach higher utilizations of storage resources?
In this article we try to answer these questions, by surveying (hopefully all) typical solutions. In particular, we will see that yes, service providers do use other solutions too, but no, alternatives definitely do not reach higher utilizations, except for when confronted with very friendly workloads. The most effective alternative, dedicated storage, may easily discard more than 90% of the available speed.
We complete this survey by summing up the results already obtained for throttling low-limit and the BFQ (Budget Fair Queueing) I/O scheduler bfq-doc in IO-control-issues.
Minimum, maximum and average bandwidth
Let’s start by describing how a production-quality service looks like, in terms of bandwidth guarantees. To this purpose, we will use one of the most widespread services as an example. Quick note: for brevity, we will mention only clients, to refer to any entity competing for storage (network in the following example), such as also containers or virtual machines.
Unless you are reading a printed or cached copy of this article, you are using an Internet connection in this very moment. If your Internet-service contract is good, it provides you with a minimum guaranteed bandwidth. But, more importantly, if the quality of the service is truly good, then most of the time you enjoy an average bandwidth that is much higher than that minimum bandwidth. Probably you chose your service provider basing mainly on the average bandwidth it delivers. Finally, a service contract provides for a maximum bandwidth, which basically depends on how much you pay.
These same facts hold for virtually any service where storage I/O is or may be involved: WEB hosting, video/audio streaming, cloud storage, containers, virtual machines, entertainment systems, …
The key feature of a good Internet service, average bandwidth, is high because of the following facts. First, only part of the total clients are active at the same time, and active clients use only a fraction of their available bandwidth on average. In contrast, the total bandwidth is sized so as to guarantee the above minimum per-client bandwidth, in the worst case of maximum total demand. So service providers use traffic-control mechanisms to redistribute the unused total bandwidth in such a way that each client gets a high average bandwidth.
How is such a standard, production-quality service scheme guaranteed when storage is involved? In particular, how effectively is unused storage speed redistributed among clients?
A simple storage example
To evaluate existing solutions for guaranteeing the above service scheme, we will use as a reference a very simple, yet concrete example. 16 clients, each issuing read requests, served by a system with the following characteristics:
-
a PLEXTOR PX-256M5S SSD as storage device, with an ext4 filesystem;
-
a 2.4GHz Intel Core i7-2760QM as CPU, and 1.3 GHz DDR3 DRAM;
-
Linux 4.18 as kernel, and BLK-MQ (the new multi-queue block layer [blk-mq]) as I/O stack (Ubuntu 18.04 as distribution, although this parameter should have no influence on the results);
-
no I/O policy enforced to control I/O, and none used as I/O scheduler (same results with MQ-DEADLINE or KYBER).
We assume that, over time, clients can issue either random or sequential read requests.
In such a system, the read peak rate of the SSD fluctuates between ~160MB/s and ~200MB/s with random I/O, while it is equal to ~515MB/s with sequential I/O. In addition, a single thread doing synchronous 4KB random reads reaches a throughput of ~23MB/s, while a single thread doing sequential reads reaches about 400MB/s.
We consider only reads, as they are the simplest type of I/O for which throughput and loss-of-control problems occur. With writes, both problems get worse. Writes:
-
tend to starve reads, because of OS-level and drive-level issues;
-
reduce throughput because they are slower than reads;
-
induce occasional very high latencies in drives.
We assume that clients have to be treated equally. So, since the device reaches a total throughput of at least 160MB/s in the worst case, and clients are 16, each client can be guaranteed at least a minimum bandwidth of 10MB/s.
Complete failure with no I/O policy enforced
The throughput reached while serving these clients is reported in Figure clients-no-control, for the following mix of client I/O:
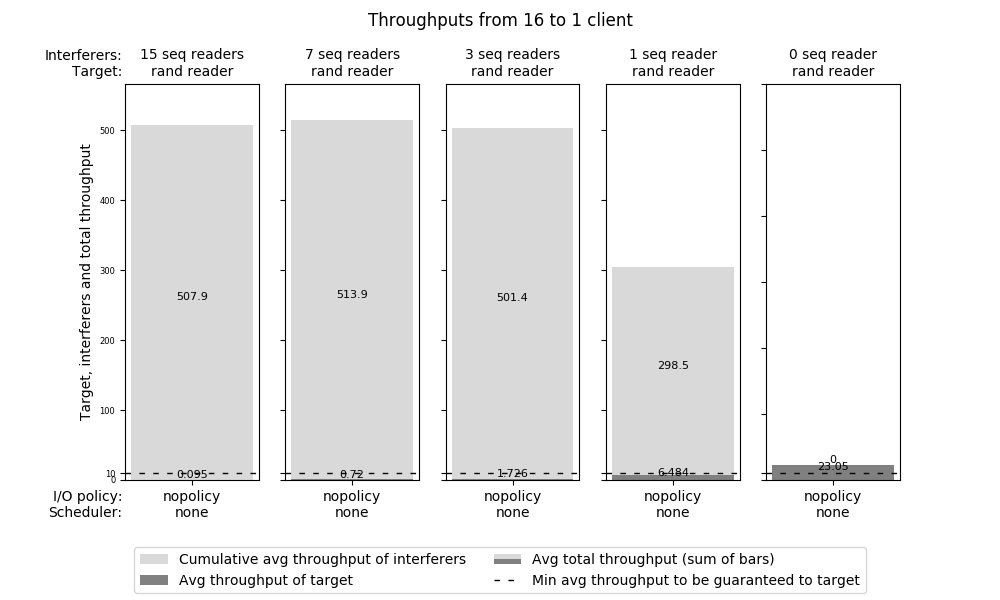{kind=link}
-
one client, called target, doing random 4KB reads;
-
all the other clients, called interferers, doing sequential reads.

Throughputs in case of no I/O control
The figure reports five plots, for decreasing total numbers of active clients (this test has been executed with the bandwidth-latency benchmark in the S suite S-suite). The leftmost plot shows that the total throughput is close to the read peak rate of the device if all 16 clients are active. But the target gets practically zero throughput!
The reason is that sequential I/O is favored by both the OS, mainly by dispatching very large I/O requests for the sequential readers, and by the in-drive I/O scheduler, by letting sequential I/O almost always cut in front of random I/O (because sequential I/O makes the drive reach its highest-possible speed). The problem remains serious with 7 or even just 3 sequential readers.
List of common solutions for guaranteeing a minimum bandwidth
The above failure highlights that, without countermeasures, serious bandwidth problems may occur. These problems motivate the following, hopefully exhaustive, list of solutions (two of the following items have been the focus of my previous article IO-control-issues, see the end of this section):
-
Limit throughput of bandwidth hogs
-
Use the proportional-share policy with the CFQ(Completely Fair Queueing) I/O scheduler io-controller, and reduce the weight of bandwidth hogs
-
Use the throttling I/O policy with low limits low-limit
-
Use dedicated storage
-
Use the proportional-share policy with the BFQ I/O scheduler bfq-doc
This list does not include the newly proposed I/O latency cgroups controller io-lat-controller, because the latter is not aimed at guaranteeing per-client bandwidths.
These solutions are meant to guaranteeing a minimum per-client bandwidth, and of delivering a hopefully higher average per-client bandwidth. As for the third problem, namely limiting the maximum bandwidths of clients on a per-contract basis, it can be solved naturally by adding per-client throttling on top of any of the above solutions. For brevity, we discuss the final, complete result only for the two most cost-effective solutions above: low limits and proportional share over BFQ.
We analyze solutions separately, but some of them could be combined together.
The low limits and bfq solutions have been already analyzed in depth in my previous article IO-control-issues, in terms of total throughput and of minimum bandwidth guaranteed to each client. In this article we summarize results for these solutions, and, most importantly, we relate the success/failure of these solutions in reaching a high total throughput, which in itself may be of no interest for a service provider, with the success/failure in guaranteeing a high average bandwidth to each client.
Limit throughput of bandwidth hogs
The Linux throttling I/O policy io-controller allows a maximum-bandwidth limit, max limit for brevity, to be set for the I/O of any group of processes.
Max limits are the most used I/O-control mechanism for addressing bandwidth issues: offended clients, such as the target in Figure clients-no-control, are given back their expected bandwidths, by detecting and limiting bandwidth hogs with max limits.
Unfortunately, if/when bandwidth hogs actually use much less bandwidth than their max limit, the bandwidth that they leave unused cannot be reclaimed by other active groups. Thus max limits are not a good solution for delivering high average bandwidths when some clients are inactive. One may think of changing max limits dynamically, to maximize per-client average bandwidths. Indeed, this is exactly what the low limits mechanism does, as explained in Section (#sec:Throttling with low limits).
In addition, the effectiveness of max limits is rigidly tied to the workload at hand. If some characteristic of the workload changes, e.g., the hog moves elsewhere, minimum-bandwidth guarantees may be lost. Finally, max limits also suffer from loss of control with writes, as shown in my previous article IO-control-issues.
On the opposite end, max limits find their natural use in limiting maximum bandwidths on a per-contract basis, as discussed in the description of a complete solution.
Proportional-share policy on CFQ
The other I/O policy available in Linux, proportional share io-controller, expects each group to be associated with a weight, and targets per-group weighted fairness.
In legacy BLK (the legacy, single-queue block layer), this policy is implemented by the CFQ I/O scheduler, which, in its turn, guarantees time fairness: each group is granted access to storage for a fraction of time proportional to the weight of the group. So, to reduce the problems caused by a bandwidth hog, an administrator can reduce the weight of the hog and/or increase the weights of the suffering clients.
This solution cannot provide definite minimum-bandwidth guarantees (e.g.: at least 10MB/s for each client). Yet, the most serious problem is that CFQ fails to control bandwidths with flash-based storage, especially on drives featuring command queueing. It is then used mainly to mitigate bandwidth issues with rotational devices.
Throttling with low limits
Because of the above throughput drawbacks of max limits, an opposite, still experimental, low limit mechanism has been added to the throttling policy low-limit. If a group is assigned such a low limit, then the throttling policy automatically, and dynamically, limits the I/O of the other groups in such a way to guarantee to the group a minimum bandwidth equal to its assigned low limit.
Unfortunately, as shown in detail in IO-control-issues, this mechanism easily throws away about 80% of the available storage speed, and fails to guarantee limits themselve. In particular, this happens with heterogeneous workloads, i.e., with mixes of, e.g., random and sequential I/O, and/or read and writes. In contrast, low limits are extremely effective with purely random workloads, for which they reach 100% of the storage speed.
Low limits have a hard time controlling I/O, intuitively, for the same reasons why we often have a hard time getting the shower temperature right. The quantities to control, namely group bandwidths, vary non linearly, and with variable delays, with respect to the changes of per-group max limits performed by the mechanism.
In the end, low limits are a little effective solution, in general, for getting high per-client average bandwidths. But they are extremely effective in case of homogenous workloads, especially if made of totally or mostly random I/O.
Dedicated storage
Service providers often devote a pool of high-performance storage units only to the I/O of the clients. A distributed filesystem may glue units together.
Such a dedicated storage can be made as reliable as desired in guaranteeing minimum bandwidths and providing high average bandwidths, without any I/O control. In fact, by properly sizing the number and the speed of the storage units, the utilization of each unit can be made so low that, while there is pending I/O for a given client, so little I/O from other clients may be pending, or arrive and possibly cut in front, that the I/O of the client will happen to be served as quickly as desired.
Thus the main performance parameter for this solution is the utilization that can be reached without breaking bandwidth guarantees. To evaluate this parameter, we start by noting that an administrator typically controls the load on each unit by deciding the number of clients served by that unit.
With a low number of clients, a high utilization can be reached only if all or most clients do sequential I/O. In contrast, in Figure clients-no-control, with the random I/O of the target served alone, the device reaches less than 7% of the throughput it reaches with just two clients.
Proportional-share policy on BFQ
In BLK-MQ, the proportional-share policy is implemented by the BFQ I/O scheduler bfq-doc. Differently from low limits, BFQ reliably guarantees target minimum bandwidths. As for throughput, BFQ reaches about 90% of the storage speed in the worst-case, namely for workloads made of purely random I/O. Thus BFQ seems an effective solution for providing each client with a high average bandwidth.
BFQ is however overcome by low limits for purely random I/O, for which low limits reach 100% of the speed. Still, not reaching full utilization may be little relevant in production-quality environments. For reliability, storage is typically redundant in these environments, and no single storage unit is fully utilized, so as to mitigate service degradation when some unit fails.
Main problems arise with very fast storage. The above 10% loss of throughput of BFQ is due to a higher execution overhead than low limits. This overhead becomes a barrier to speeds above 400 KIOPS, on commodity CPUs bfq-doc. Work is in progress on addressing this issue.
A complete, general solution
Low limits and proportional share, enforced by BFQ, are evidently the most general solutions for guaranteeing minimum bandwidths. To get a complete solution, maximum bandwidths must be enforced too. This can be done by just adding max limits on top of low limits or of proportional share, with the following final result.
Minimum bandwidth:
- Reliably guaranteed by low limits with homogenous workloads, or by BFQ with any workload.
High average bandwidth:
- Fully reached by low limits with homogeneous workloads, or quasi-optimally reached by BFQ, because BFQ
- keeps throughput in the range 90-100% of the available speed;
- systematically distributes throughput among the only active clients according to their weights.
Maximum bandwidth:
- Limited with max limits. Should limits be so low to cause losses of throughput during light-load periods, that would actually be a consequence of the commercial strategy of the provider, and not of intrinsic problems of the mechanism.
Conclusion
Current solutions for guaranteeing I/O bandwidths can be compared to drivers of buses that carry passengers belonging to different groups. For each ride, these bus drivers are able to select passengers so as to guarantee that at least a given minimum number of persons per group get to their destinations every hour.
With homogeneous passengers, buses can run full. But, with general mixes of passengers, buses will run almost empty, with no more than 10-20% of the seats occupied. So a lot of buses are needed to tranport all the daily passengers. In addition, in some situations these bus drivers choose incorrectly, and end up not carrying enough people per hour for some unlucky group.
There is now a new bus driver, BFQ, who can finally drive buses with 90-100% of the seats occupied, and with any mix of passengers always correctly selected. So, in general,BFQ enables all the daily passengers to be moved using five to ten times less buses than those needed previously. On the downside, BFQ cannot reach full seat utilization with some types of passengers, and cannot drive next-generation super fast buses (there is development to try to improve on this front).
So, the future of I/O management mostly depends on which bus drivers companies will prefer to entrust their vehicles to…